LightViT: Towards Light-Weight Convolution-Free Vision Transformers
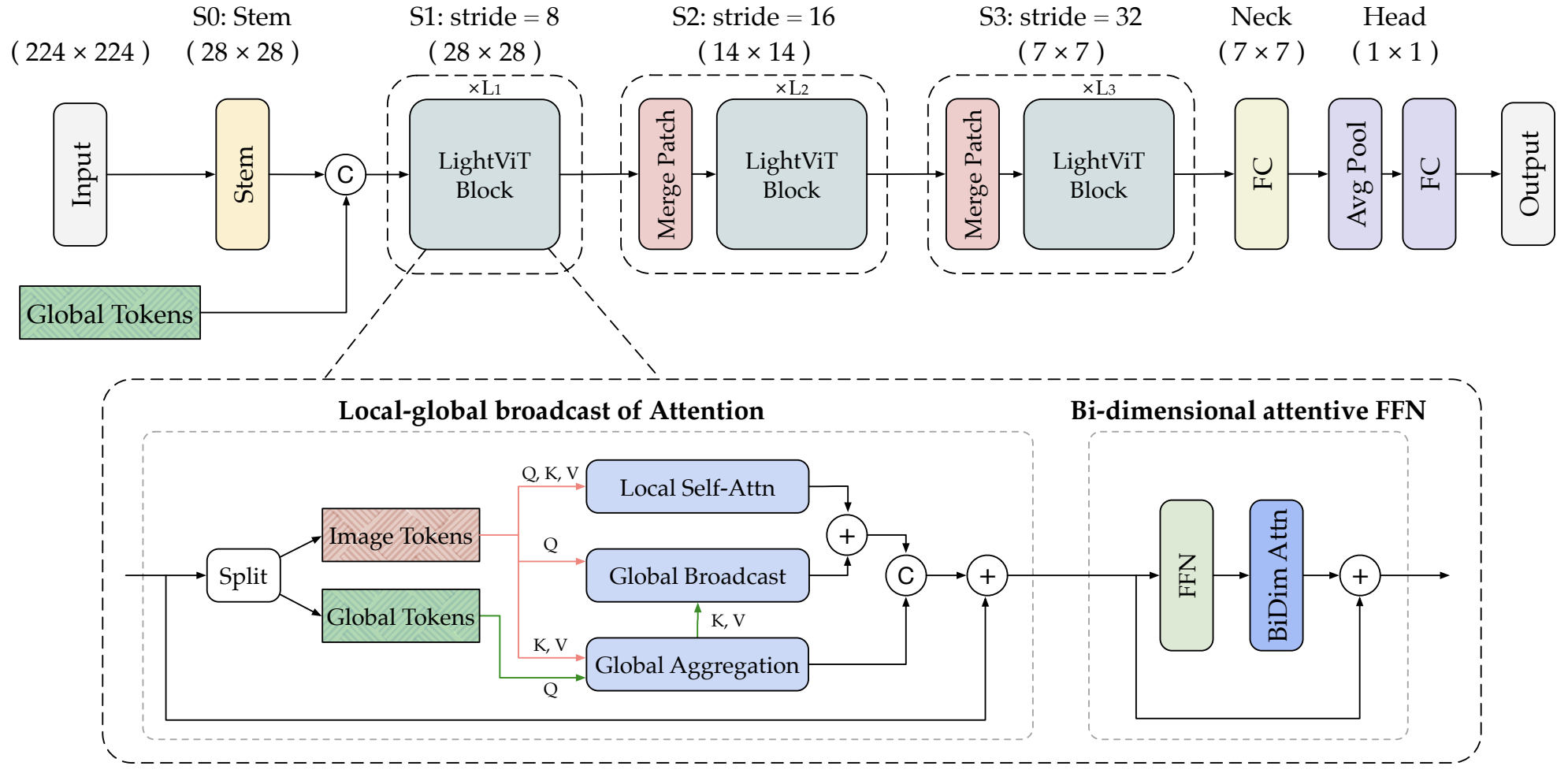
Vision transformers (ViTs) are usually considered to be less light-weight than convolutional neural networks (CNNs) due to the lack of inductive bias. Recent works thus resort to convolutions as a plug-and-play module and embed them in various ViT counterparts. In this paper, we argue that the convolutional kernels perform information aggregation to connect all tokens; however, they would be actually unnecessary for light-weight ViTs if this explicit aggregation could function in a more homogeneous way. Inspired by this, we present LightViT as a new family of light-weight ViTs to achieve better accuracy-efficiency balance upon the pure transformer blocks without convolution. Concretely, we introduce a global yet efficient aggregation scheme into both self-attention and feed-forward network (FFN) of ViTs, where additional learnable tokens are introduced to capture global dependencies; and bi-dimensional channel and spatial attentions are imposed over token embeddings. Experiments show that our model achieves significant improvements on image classification, object detection, and semantic segmentation tasks. For example, our LightViT-T achieves 78.7% accuracy on ImageNet with only 0.7G FLOPs, outperforming PVTv2-B0 by 8.2% while 11% faster on GPU. Code is available at https://github.com/hunto/LightViT.
PDF Abstract




 ImageNet
ImageNet
 MS COCO
MS COCO
