Localized Vision-Language Matching for Open-vocabulary Object Detection
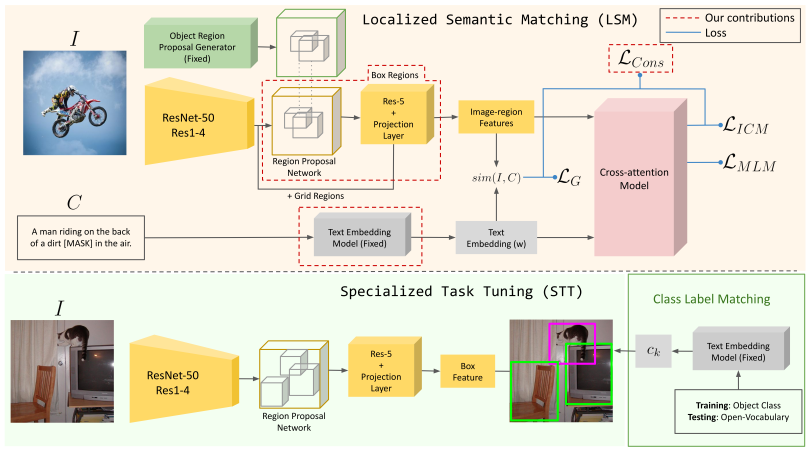
In this work, we propose an open-vocabulary object detection method that, based on image-caption pairs, learns to detect novel object classes along with a given set of known classes. It is a two-stage training approach that first uses a location-guided image-caption matching technique to learn class labels for both novel and known classes in a weakly-supervised manner and second specializes the model for the object detection task using known class annotations. We show that a simple language model fits better than a large contextualized language model for detecting novel objects. Moreover, we introduce a consistency-regularization technique to better exploit image-caption pair information. Our method compares favorably to existing open-vocabulary detection approaches while being data-efficient. Source code is available at https://github.com/lmb-freiburg/locov .
PDF Abstract






 ImageNet
ImageNet
 MS COCO
MS COCO
 COCO Captions
COCO Captions
 VAW
VAW
 OVAD benchmark
OVAD benchmark

