MaskDiffusion: Exploiting Pre-trained Diffusion Models for Semantic Segmentation
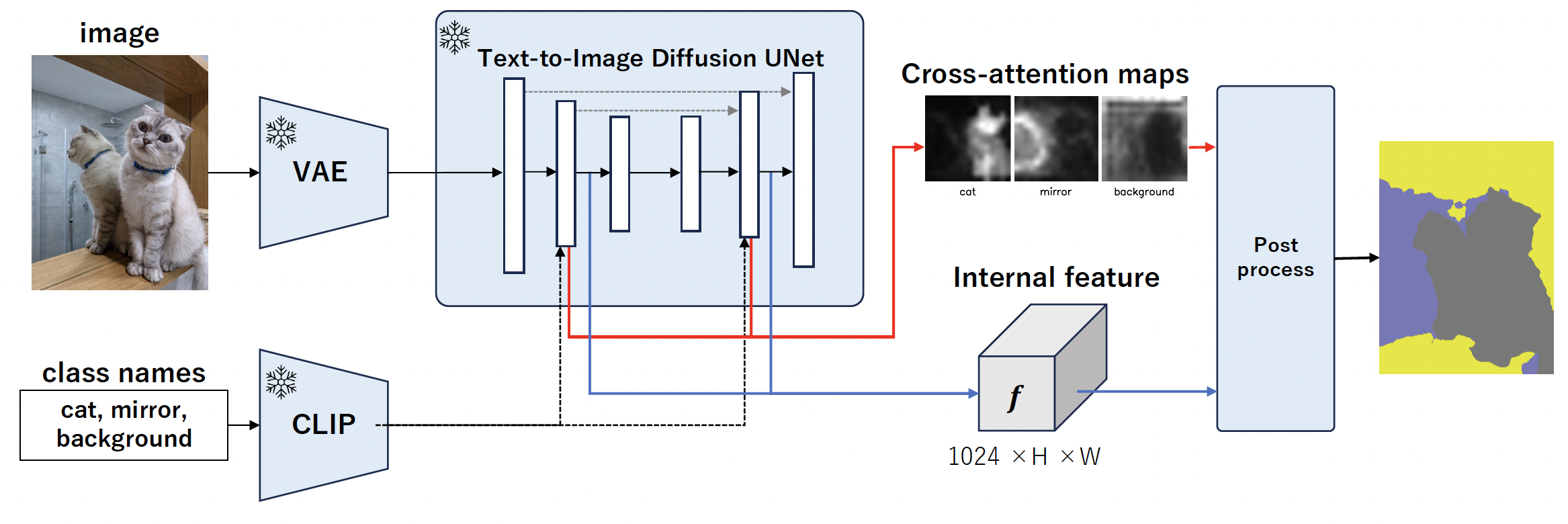
Semantic segmentation is essential in computer vision for various applications, yet traditional approaches face significant challenges, including the high cost of annotation and extensive training for supervised learning. Additionally, due to the limited predefined categories in supervised learning, models typically struggle with infrequent classes and are unable to predict novel classes. To address these limitations, we propose MaskDiffusion, an innovative approach that leverages pretrained frozen Stable Diffusion to achieve open-vocabulary semantic segmentation without the need for additional training or annotation, leading to improved performance compared to similar methods. We also demonstrate the superior performance of MaskDiffusion in handling open vocabularies, including fine-grained and proper noun-based categories, thus expanding the scope of segmentation applications. Overall, our MaskDiffusion shows significant qualitative and quantitative improvements in contrast to other comparable unsupervised segmentation methods, i.e. on the Potsdam dataset (+10.5 mIoU compared to GEM) and COCO-Stuff (+14.8 mIoU compared to DiffSeg). All code and data will be released at https://github.com/Valkyrja3607/MaskDiffusion.
PDF Abstract


 Cityscapes
Cityscapes
 COCO-Stuff
COCO-Stuff
