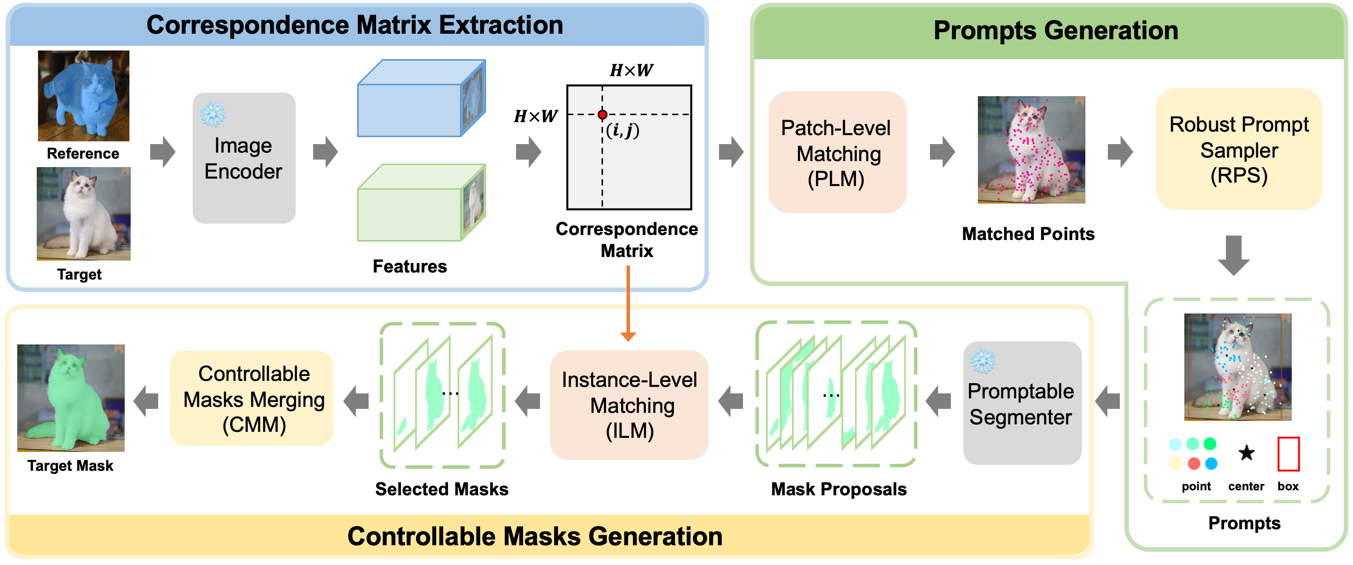
Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching
Powered by large-scale pre-training, vision foundation models exhibit significant potential in open-world image understanding. However, unlike large language models that excel at directly tackling various language tasks, vision foundation models require a task-specific model structure followed by fine-tuning on specific tasks. In this work, we present Matcher, a novel perception paradigm that utilizes off-the-shelf vision foundation models to address various perception tasks. Matcher can segment anything by using an in-context example without training. Additionally, we design three effective components within the Matcher framework to collaborate with these foundation models and unleash their full potential in diverse perception tasks. Matcher demonstrates impressive generalization performance across various segmentation tasks, all without training. For example, it achieves 52.7% mIoU on COCO-20$^i$ with one example, surpassing the state-of-the-art specialist model by 1.6%. In addition, Matcher achieves 33.0% mIoU on the proposed LVIS-92$^i$ for one-shot semantic segmentation, outperforming the state-of-the-art generalist model by 14.4%. Our visualization results further showcase the open-world generality and flexibility of Matcher when applied to images in the wild. Our code can be found at https://github.com/aim-uofa/Matcher.
PDF Abstract


 MS COCO
MS COCO
 DAVIS
DAVIS
 LVIS
LVIS
 DAVIS 2017
DAVIS 2017
 DAVIS 2016
DAVIS 2016
 PASCAL-Part
PASCAL-Part
 FSS-1000
FSS-1000
 PACO
PACO
