MIMIC-IT: Multi-Modal In-Context Instruction Tuning
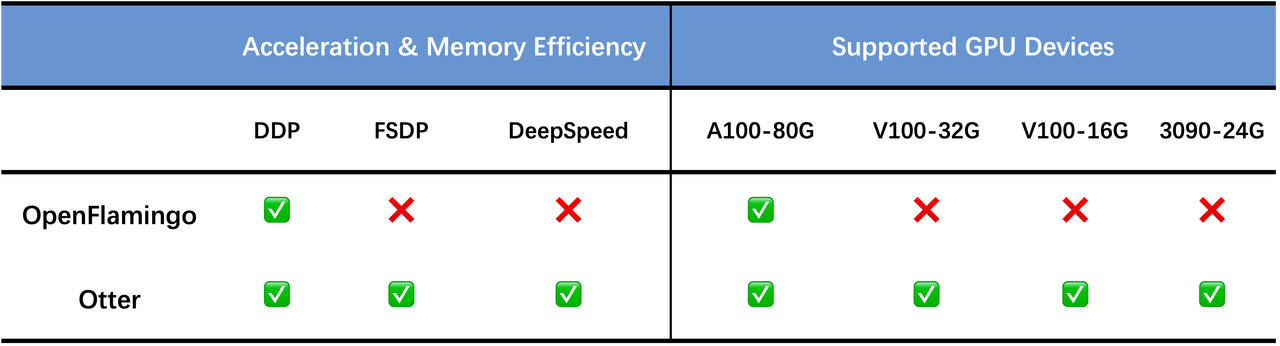
High-quality instructions and responses are essential for the zero-shot performance of large language models on interactive natural language tasks. For interactive vision-language tasks involving intricate visual scenes, a large quantity of diverse and creative instruction-response pairs should be imperative to tune vision-language models (VLMs). Nevertheless, the current availability of vision-language instruction-response pairs in terms of quantity, diversity, and creativity remains limited, posing challenges to the generalization of interactive VLMs. Here we present MultI-Modal In-Context Instruction Tuning (MIMIC-IT), a dataset comprising 2.8 million multimodal instruction-response pairs, with 2.2 million unique instructions derived from images and videos. Each pair is accompanied by multi-modal in-context information, forming conversational contexts aimed at empowering VLMs in perception, reasoning, and planning. The instruction-response collection process, dubbed as Syphus, is scaled using an automatic annotation pipeline that combines human expertise with GPT's capabilities. Using the MIMIC-IT dataset, we train a large VLM named Otter. Based on extensive evaluations conducted on vision-language benchmarks, it has been observed that Otter demonstrates remarkable proficiency in multi-modal perception, reasoning, and in-context learning. Human evaluation reveals it effectively aligns with the user's intentions. We release the MIMIC-IT dataset, instruction-response collection pipeline, benchmarks, and the Otter model.
PDF Abstract
 Spaces
Spaces

 MS COCO
MS COCO
 ScanNet
ScanNet
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 VIST
VIST
 MM-Vet
MM-Vet
 TVC
TVC

