LEAP: Learnable Pruning for Transformer-based Models
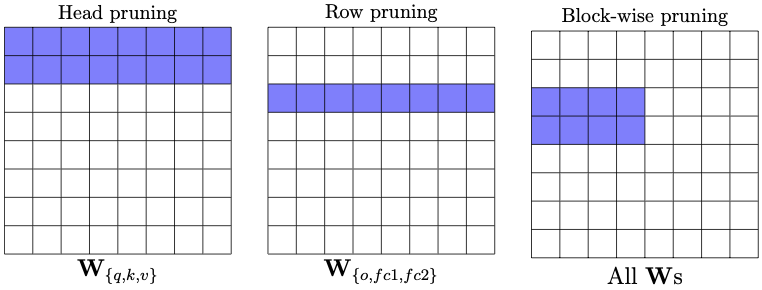
Pruning is an effective method to reduce the memory footprint and computational cost associated with large natural language processing models. However, current pruning algorithms either only focus on one pruning category, e.g., structured pruning and unstructured, or need extensive hyperparameter tuning in order to get reasonable accuracy performance. To address these challenges, we propose LEArnable Pruning (LEAP), an effective method to gradually prune the model based on thresholds learned by gradient descent. Different than previous learnable pruning methods, which utilize $L_0$ or $L_1$ penalty to indirectly affect the final pruning ratio, LEAP introduces a novel regularization function, that directly interacts with the preset target pruning ratio. Moreover, in order to reduce hyperparameter tuning, a novel adaptive regularization coefficient is deployed to control the regularization penalty adaptively. With the new regularization term and its associated adaptive regularization coefficient, LEAP is able to be applied for different pruning granularity, including unstructured pruning, structured pruning, and hybrid pruning, with minimal hyperparameter tuning. We apply LEAP for BERT models on QQP/MNLI/SQuAD for different pruning settings. Our result shows that for all datasets, pruning granularity, and pruning ratios, LEAP achieves on-par or better results as compared to previous heavily hand-tuned methods.
PDF Abstract

 SQuAD
SQuAD
