MoST: Motion Style Transformer between Diverse Action Contents
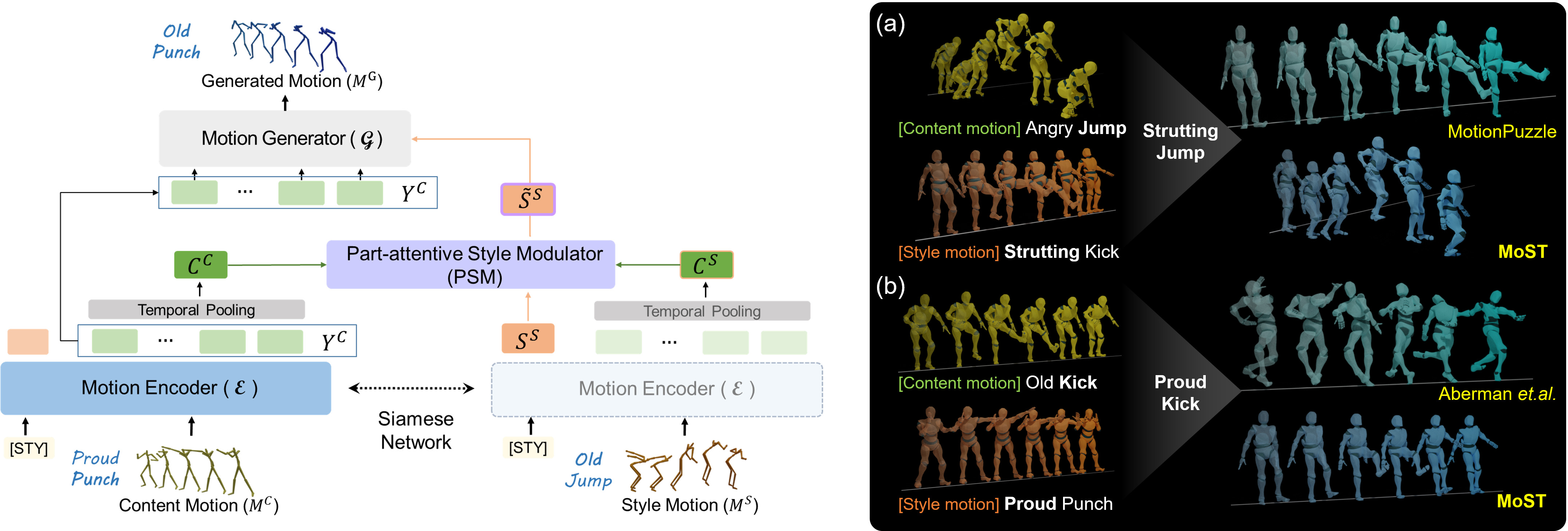
While existing motion style transfer methods are effective between two motions with identical content, their performance significantly diminishes when transferring style between motions with different contents. This challenge lies in the lack of clear separation between content and style of a motion. To tackle this challenge, we propose a novel motion style transformer that effectively disentangles style from content and generates a plausible motion with transferred style from a source motion. Our distinctive approach to achieving the goal of disentanglement is twofold: (1) a new architecture for motion style transformer with `part-attentive style modulator across body parts' and `Siamese encoders that encode style and content features separately'; (2) style disentanglement loss. Our method outperforms existing methods and demonstrates exceptionally high quality, particularly in motion pairs with different contents, without the need for heuristic post-processing. Codes are available at https://github.com/Boeun-Kim/MoST.
PDF Abstract


