Multimodal Across Domains Gaze Target Detection
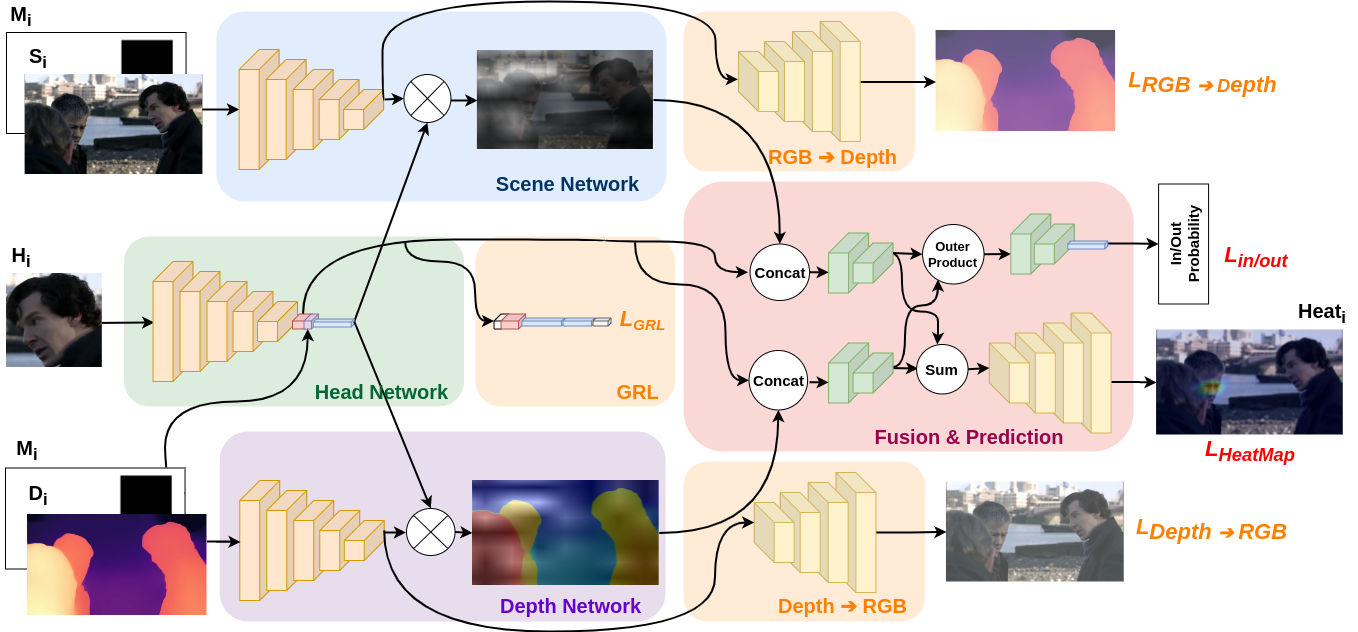
This paper addresses the gaze target detection problem in single images captured from the third-person perspective. We present a multimodal deep architecture to infer where a person in a scene is looking. This spatial model is trained on the head images of the person-of- interest, scene and depth maps representing rich context information. Our model, unlike several prior art, do not require supervision of the gaze angles, do not rely on head orientation information and/or location of the eyes of person-of-interest. Extensive experiments demonstrate the stronger performance of our method on multiple benchmark datasets. We also investigated several variations of our method by altering joint-learning of multimodal data. Some variations outperform a few prior art as well. First time in this paper, we inspect domain adaption for gaze target detection, and we empower our multimodal network to effectively handle the domain gap across datasets. The code of the proposed method is available at https://github.com/francescotonini/multimodal-across-domains-gaze-target-detection.
PDF Abstract

 Places205
Places205
 GazeFollow
GazeFollow
 GOO
GOO
