Multimodal Scale Consistency and Awareness for Monocular Self-Supervised Depth Estimation
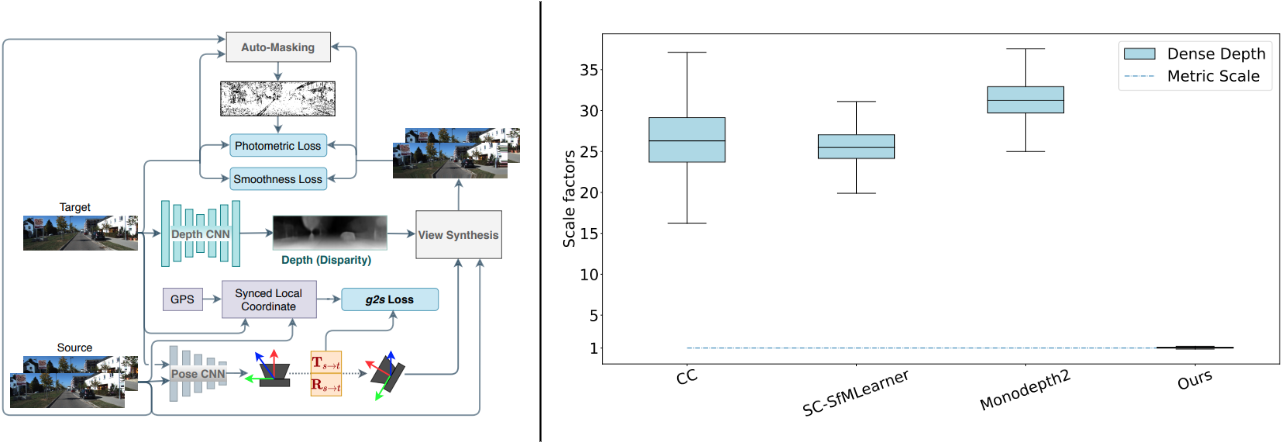
Dense depth estimation is essential to scene-understanding for autonomous driving. However, recent self-supervised approaches on monocular videos suffer from scale-inconsistency across long sequences. Utilizing data from the ubiquitously copresent global positioning systems (GPS), we tackle this challenge by proposing a dynamically-weighted GPS-to-Scale (g2s) loss to complement the appearance-based losses. We emphasize that the GPS is needed only during the multimodal training, and not at inference. The relative distance between frames captured through the GPS provides a scale signal that is independent of the camera setup and scene distribution, resulting in richer learned feature representations. Through extensive evaluation on multiple datasets, we demonstrate scale-consistent and -aware depth estimation during inference, improving the performance even when training with low-frequency GPS data.
PDF AbstractCode





Datasets
 Cityscapes
Cityscapes
 KITTI
KITTI
 Make3D
Make3D
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Monocular Depth Estimation | KITTI Eigen split unsupervised | G2S (MD2-M-R18-pp-640 x 192) | absolute relative error | 0.109 | # 29 |
