MVPTR: Multi-Level Semantic Alignment for Vision-Language Pre-Training via Multi-Stage Learning
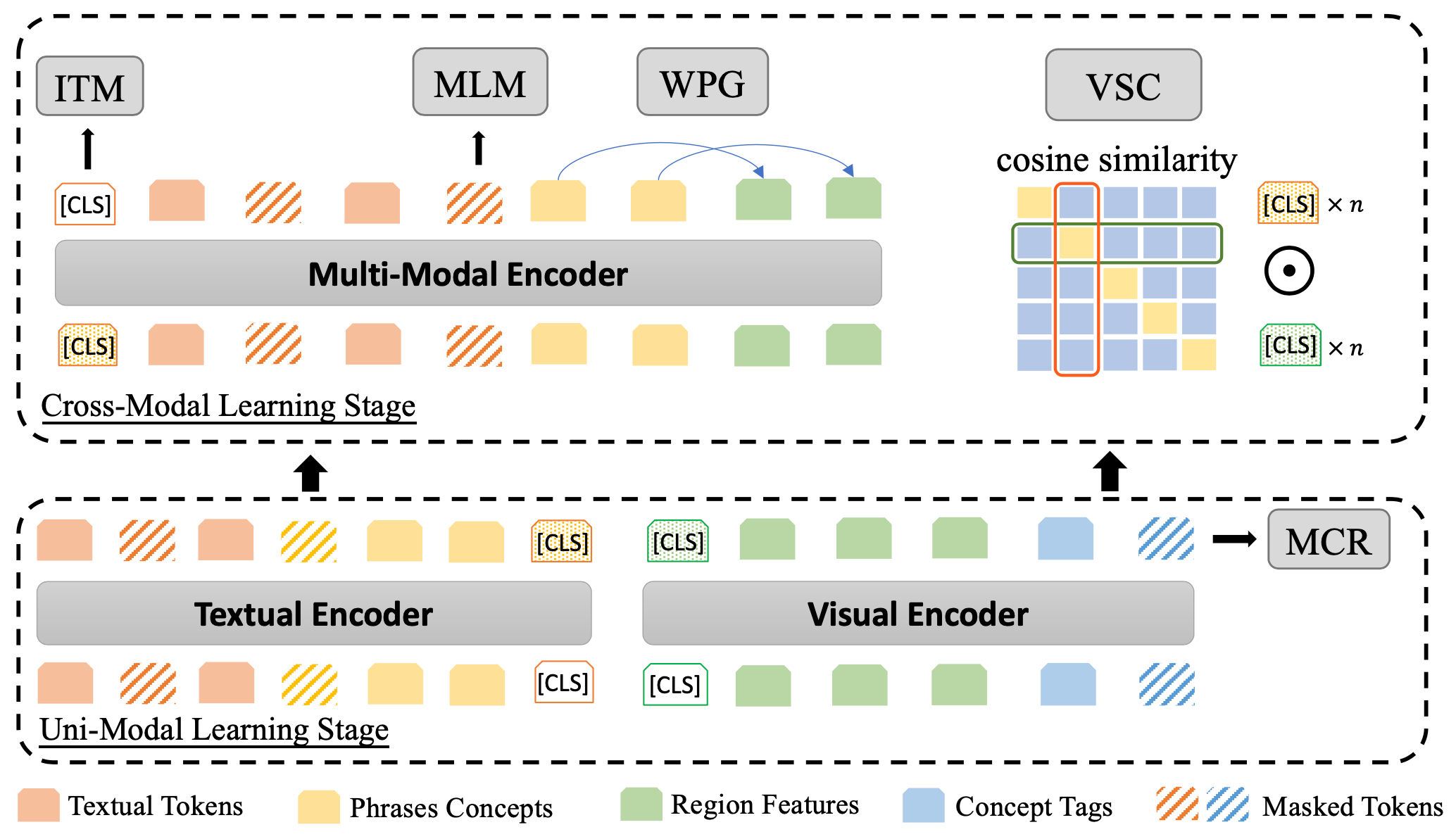
Previous vision-language pre-training models mainly construct multi-modal inputs with tokens and objects (pixels) followed by performing cross-modality interaction between them. We argue that the input of only tokens and object features limits high-level semantic alignment like phrase-to-region grounding. Meanwhile, multi-level alignments are inherently consistent and able to facilitate the representation learning synergistically. Therefore, in this paper, we propose to learn Multi-level semantic alignment for Vision-language Pre-TRaining (MVPTR). In MVPTR, we follow the nested structure of both modalities to introduce concepts as high-level semantics. To ease the learning from multi-modal multi-level inputs, our framework is split into two stages, the first stage focuses on intra-modality multi-level representation learning, the second enforces interactions across modalities via both coarse-grained and fine-grained semantic alignment tasks. In addition to the commonly used image-text matching and masked language model tasks, we introduce a masked concept recovering task in the first stage to enhance the concept representation learning, and two more tasks in the second stage to explicitly encourage multi-level alignments across modalities. Our code is available at https://github.com/Junction4Nako/mvp_pytorch.
PDF Abstract



 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Flickr30k
Flickr30k
