
ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities
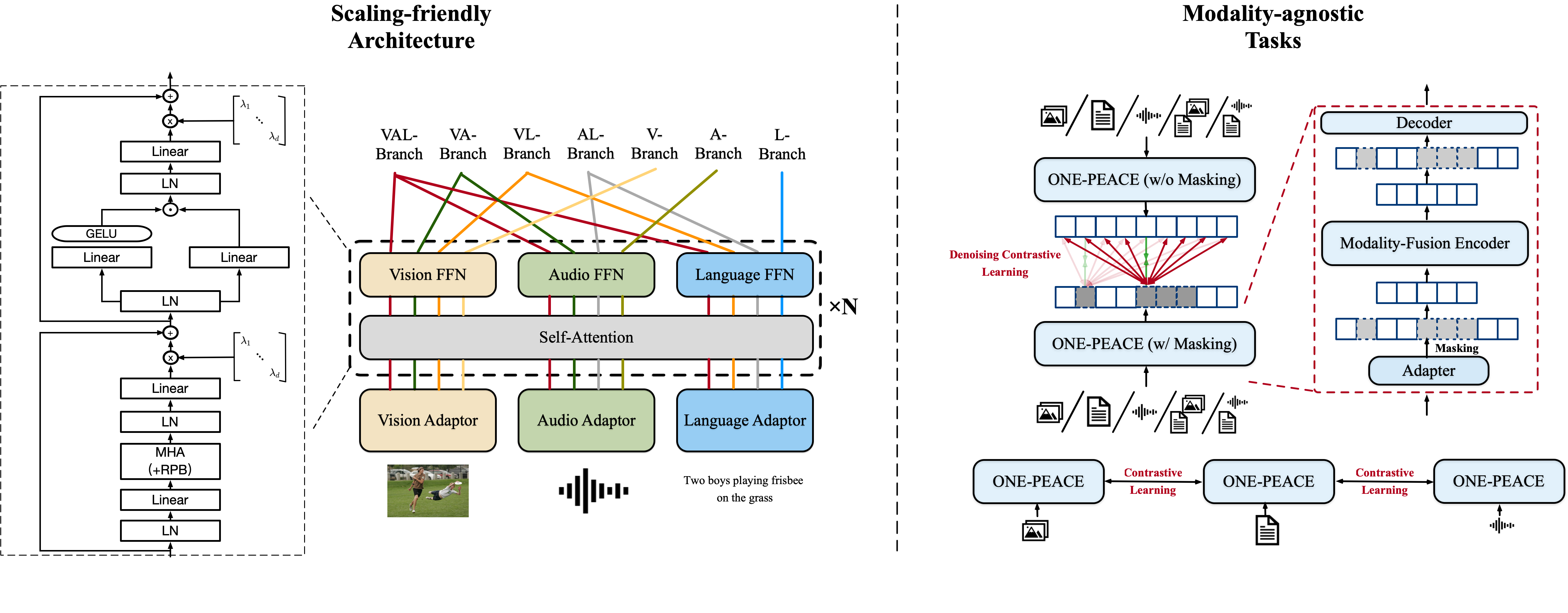
In this work, we explore a scalable way for building a general representation model toward unlimited modalities. We release ONE-PEACE, a highly extensible model with 4B parameters that can seamlessly align and integrate representations across vision, audio, and language modalities. The architecture of ONE-PEACE comprises modality adapters, shared self-attention layers, and modality FFNs. This design allows for the easy extension of new modalities by adding adapters and FFNs, while also enabling multi-modal fusion through self-attention layers. To pretrain ONE-PEACE, we develop two modality-agnostic pretraining tasks, cross-modal aligning contrast and intra-modal denoising contrast, which align the semantic space of different modalities and capture fine-grained details within modalities concurrently. With the scaling-friendly architecture and pretraining tasks, ONE-PEACE has the potential to expand to unlimited modalities. Without using any vision or language pretrained model for initialization, ONE-PEACE achieves leading results on a wide range of uni-modal and multi-modal tasks, including image classification (ImageNet), semantic segmentation (ADE20K), audio-text retrieval (AudioCaps, Clotho), audio classification (ESC-50, FSD50K, VGGSound), audio question answering (AVQA), image-text retrieval (MSCOCO, Flickr30K), and visual grounding (RefCOCO/+/g). Code is available at https://github.com/OFA-Sys/ONE-PEACE.
PDF AbstractCode
 Spaces
Spaces

Tasks
 Action Classification
Action Classification
 AudioCaps
Audio Classification
Audio Question Answering
Audio to Text Retrieval
Audio-Visual Question Answering (AVQA)
AudioCaps
Audio Classification
Audio Question Answering
Audio to Text Retrieval
Audio-Visual Question Answering (AVQA)
 Denoising
Denoising
 Image Classification
Image-to-Text Retrieval
Image Classification
Image-to-Text Retrieval
 Question Answering
Referring Expression Comprehension
Retrieval
Question Answering
Referring Expression Comprehension
Retrieval
 Self-Supervised Image Classification
Self-Supervised Image Classification
 Semantic Segmentation
Text Retrieval
Text to Audio Retrieval
Semantic Segmentation
Text Retrieval
Text to Audio Retrieval
 Visual Grounding
Visual Grounding
 Visual Question Answering (VQA)
Zero-Shot Environment Sound Classification
Visual Question Answering (VQA)
Zero-Shot Environment Sound Classification
 ImageNet
ImageNet
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Kinetics
Kinetics
 Visual Genome
Visual Genome
 ADE20K
ADE20K
 Flickr30k
Flickr30k
 Kinetics 400
Kinetics 400
 Visual Question Answering v2.0
Visual Question Answering v2.0
 RefCOCO
RefCOCO
 ESC-50
ESC-50
 AudioCaps
AudioCaps
 VGG-Sound
VGG-Sound
 Clotho
Clotho
 FSD50K
FSD50K
Results from the Paper
 Ranked #1 on
Semantic Segmentation
on ADE20K
(using extra training data)
Ranked #1 on
Semantic Segmentation
on ADE20K
(using extra training data)
