PEM: Prototype-based Efficient MaskFormer for Image Segmentation
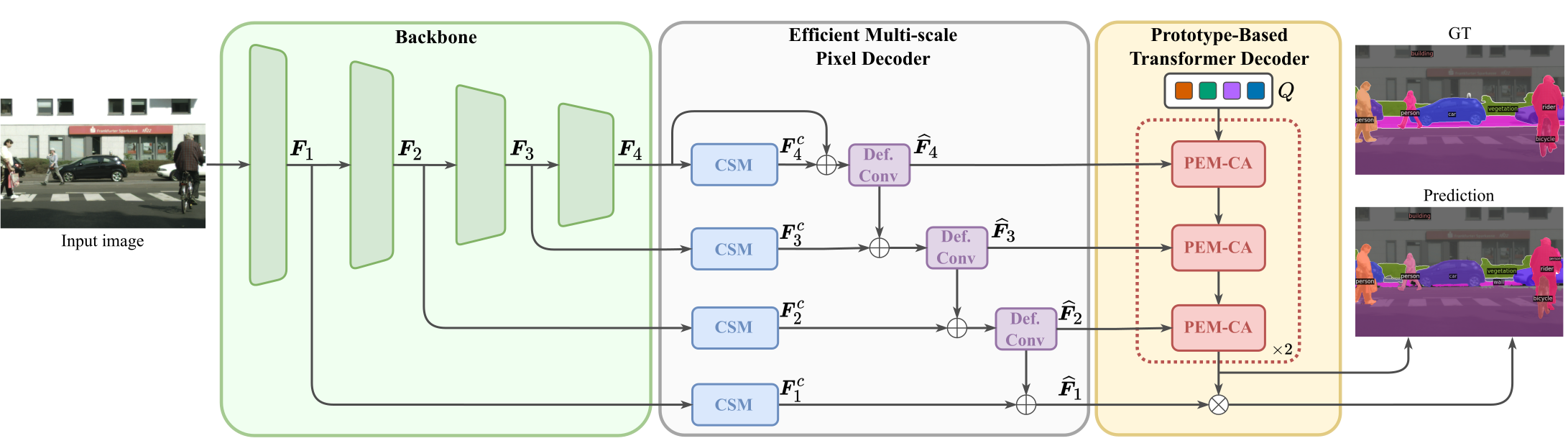
Recent transformer-based architectures have shown impressive results in the field of image segmentation. Thanks to their flexibility, they obtain outstanding performance in multiple segmentation tasks, such as semantic and panoptic, under a single unified framework. To achieve such impressive performance, these architectures employ intensive operations and require substantial computational resources, which are often not available, especially on edge devices. To fill this gap, we propose Prototype-based Efficient MaskFormer (PEM), an efficient transformer-based architecture that can operate in multiple segmentation tasks. PEM proposes a novel prototype-based cross-attention which leverages the redundancy of visual features to restrict the computation and improve the efficiency without harming the performance. In addition, PEM introduces an efficient multi-scale feature pyramid network, capable of extracting features that have high semantic content in an efficient way, thanks to the combination of deformable convolutions and context-based self-modulation. We benchmark the proposed PEM architecture on two tasks, semantic and panoptic segmentation, evaluated on two different datasets, Cityscapes and ADE20K. PEM demonstrates outstanding performance on every task and dataset, outperforming task-specific architectures while being comparable and even better than computationally-expensive baselines.
PDF Abstract



 Cityscapes
Cityscapes
 ADE20K
ADE20K
