Perspective-aware Convolution for Monocular 3D Object Detection
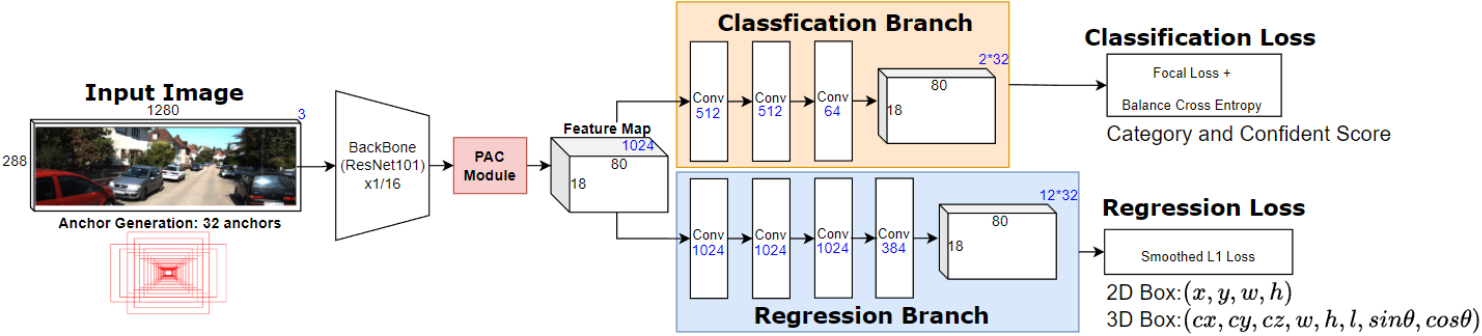
Monocular 3D object detection is a crucial and challenging task for autonomous driving vehicle, while it uses only a single camera image to infer 3D objects in the scene. To address the difficulty of predicting depth using only pictorial clue, we propose a novel perspective-aware convolutional layer that captures long-range dependencies in images. By enforcing convolutional kernels to extract features along the depth axis of every image pixel, we incorporates perspective information into network architecture. We integrate our perspective-aware convolutional layer into a 3D object detector and demonstrate improved performance on the KITTI3D dataset, achieving a 23.9\% average precision in the easy benchmark. These results underscore the importance of modeling scene clues for accurate depth inference and highlight the benefits of incorporating scene structure in network design. Our perspective-aware convolutional layer has the potential to enhance object detection accuracy by providing more precise and context-aware feature extraction.
PDF Abstract




