Policy Gradient Methods in the Presence of Symmetries and State Abstractions
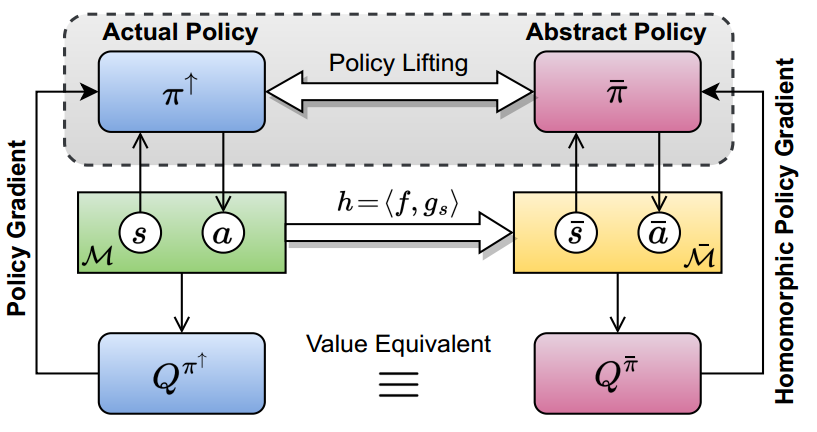
Reinforcement learning (RL) on high-dimensional and complex problems relies on abstraction for improved efficiency and generalization. In this paper, we study abstraction in the continuous-control setting, and extend the definition of Markov decision process (MDP) homomorphisms to the setting of continuous state and action spaces. We derive a policy gradient theorem on the abstract MDP for both stochastic and deterministic policies. Our policy gradient results allow for leveraging approximate symmetries of the environment for policy optimization. Based on these theorems, we propose a family of actor-critic algorithms that are able to learn the policy and the MDP homomorphism map simultaneously, using the lax bisimulation metric. Finally, we introduce a series of environments with continuous symmetries to further demonstrate the ability of our algorithm for action abstraction in the presence of such symmetries. We demonstrate the effectiveness of our method on our environments, as well as on challenging visual control tasks from the DeepMind Control Suite. Our method's ability to utilize MDP homomorphisms for representation learning leads to improved performance, and the visualizations of the latent space clearly demonstrate the structure of the learned abstraction.
PDF Abstract


 DeepMind Control Suite
DeepMind Control Suite
