Pre-training Vision Transformers with Very Limited Synthesized Images
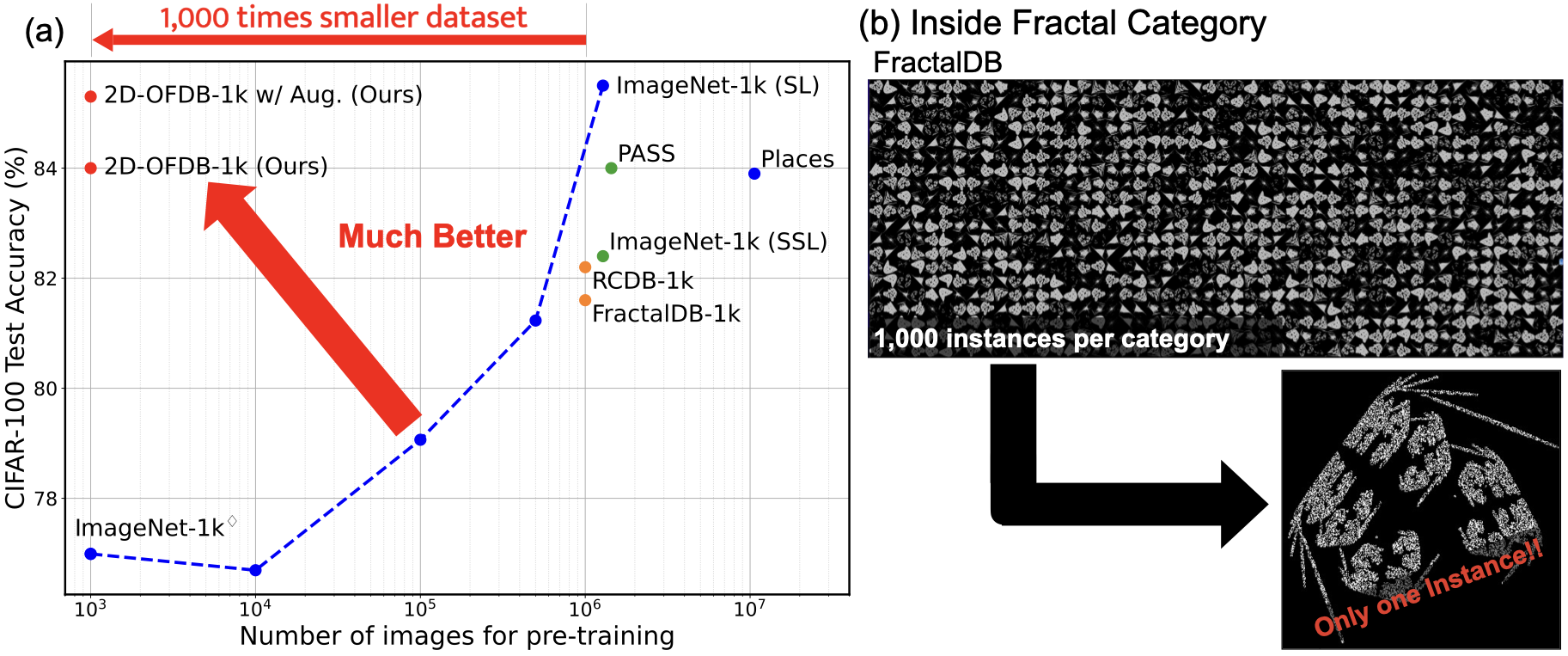
Formula-driven supervised learning (FDSL) is a pre-training method that relies on synthetic images generated from mathematical formulae such as fractals. Prior work on FDSL has shown that pre-training vision transformers on such synthetic datasets can yield competitive accuracy on a wide range of downstream tasks. These synthetic images are categorized according to the parameters in the mathematical formula that generate them. In the present work, we hypothesize that the process for generating different instances for the same category in FDSL, can be viewed as a form of data augmentation. We validate this hypothesis by replacing the instances with data augmentation, which means we only need a single image per category. Our experiments shows that this one-instance fractal database (OFDB) performs better than the original dataset where instances were explicitly generated. We further scale up OFDB to 21,000 categories and show that it matches, or even surpasses, the model pre-trained on ImageNet-21k in ImageNet-1k fine-tuning. The number of images in OFDB is 21k, whereas ImageNet-21k has 14M. This opens new possibilities for pre-training vision transformers with much smaller datasets.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract

 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 CUB-200-2011
CUB-200-2011
 Oxford 102 Flower
Oxford 102 Flower
 Places
Places
 DTD
DTD
 JFT-300M
JFT-300M
 PASS
PASS
