Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks
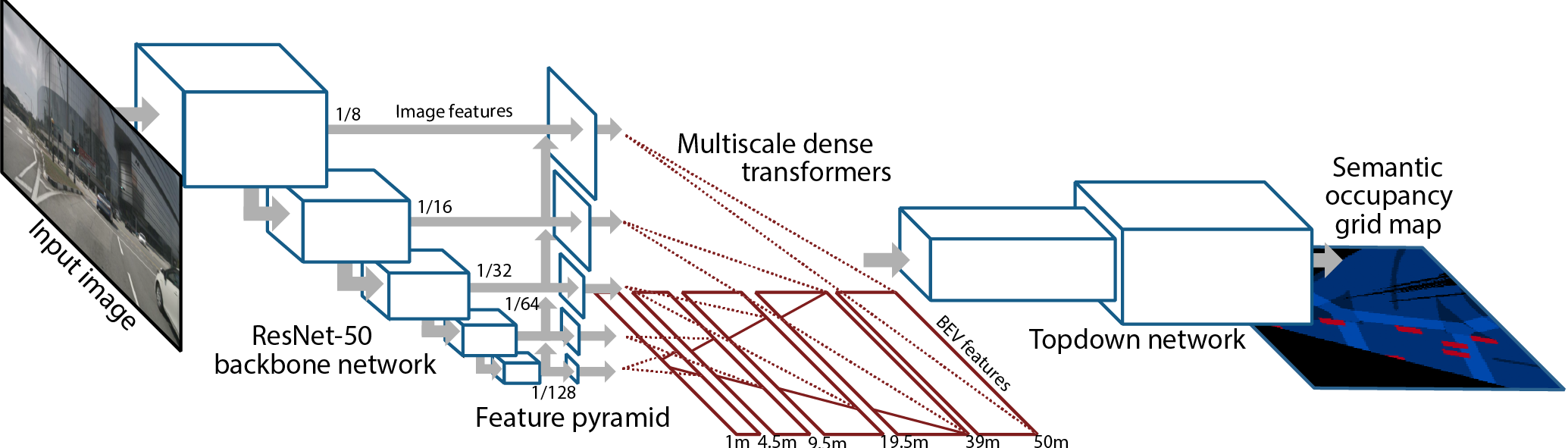
Autonomous vehicles commonly rely on highly detailed birds-eye-view maps of their environment, which capture both static elements of the scene such as road layout as well as dynamic elements such as other cars and pedestrians. Generating these map representations on the fly is a complex multi-stage process which incorporates many important vision-based elements, including ground plane estimation, road segmentation and 3D object detection. In this work we present a simple, unified approach for estimating maps directly from monocular images using a single end-to-end deep learning architecture. For the maps themselves we adopt a semantic Bayesian occupancy grid framework, allowing us to trivially accumulate information over multiple cameras and timesteps. We demonstrate the effectiveness of our approach by evaluating against several challenging baselines on the NuScenes and Argoverse datasets, and show that we are able to achieve a relative improvement of 9.1% and 22.3% respectively compared to the best-performing existing method.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract




 Cityscapes
Cityscapes
 nuScenes
nuScenes
 Argoverse
Argoverse
