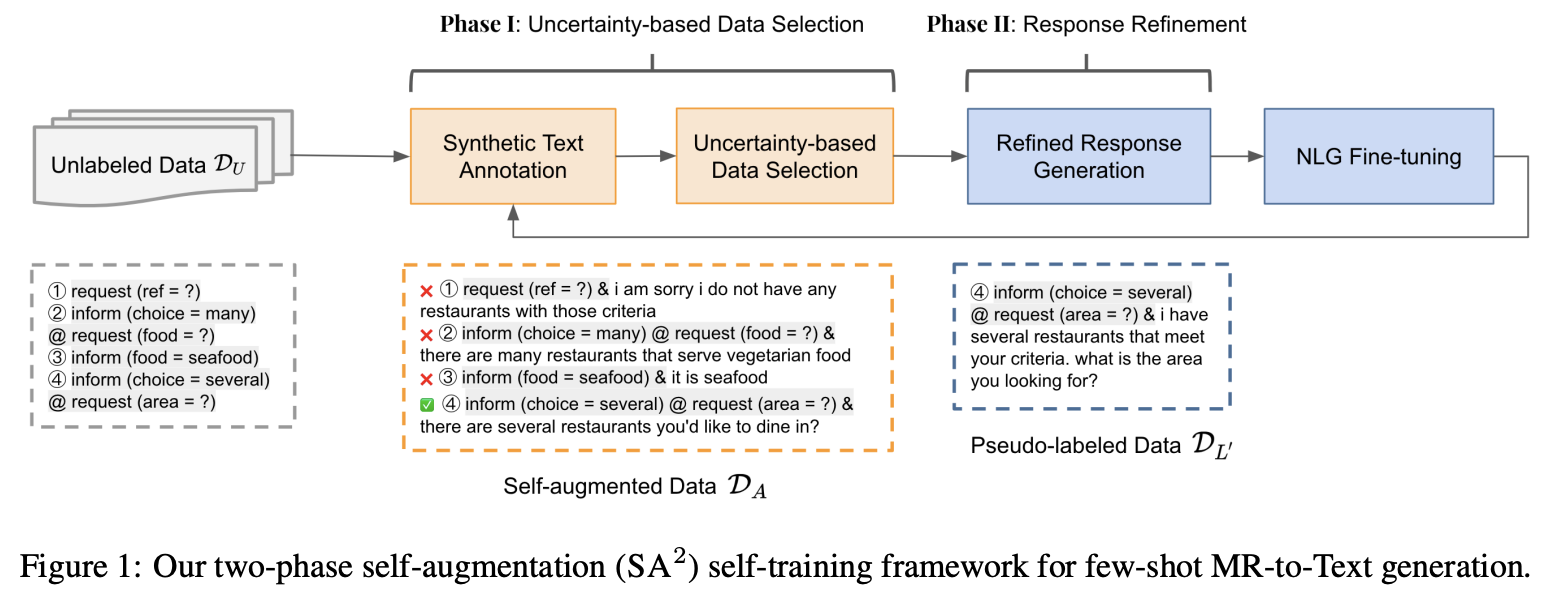
Self-training with Two-phase Self-augmentation for Few-shot Dialogue Generation
In task-oriented dialogue systems, response generation from meaning representations (MRs) often suffers from limited training examples, due to the high cost of annotating MR-to-Text pairs. Previous works on self-training leverage fine-tuned conversational models to automatically generate pseudo-labeled MR-to-Text pairs for further fine-tuning. However, some self-augmented data may be noisy or uninformative for the model to learn from. In this work, we propose a two-phase self-augmentation procedure to generate high-quality pseudo-labeled MR-to-Text pairs: the first phase selects the most informative MRs based on model's prediction uncertainty; with the selected MRs, the second phase generates accurate responses by aggregating multiple perturbed latent representations from each MR. Empirical experiments on two benchmark datasets, FewShotWOZ and FewShotSGD, show that our method generally outperforms existing self-training methods on both automatic and human evaluations.
PDF Abstract




 MultiWOZ
MultiWOZ
