Sieve: Multimodal Dataset Pruning Using Image Captioning Models
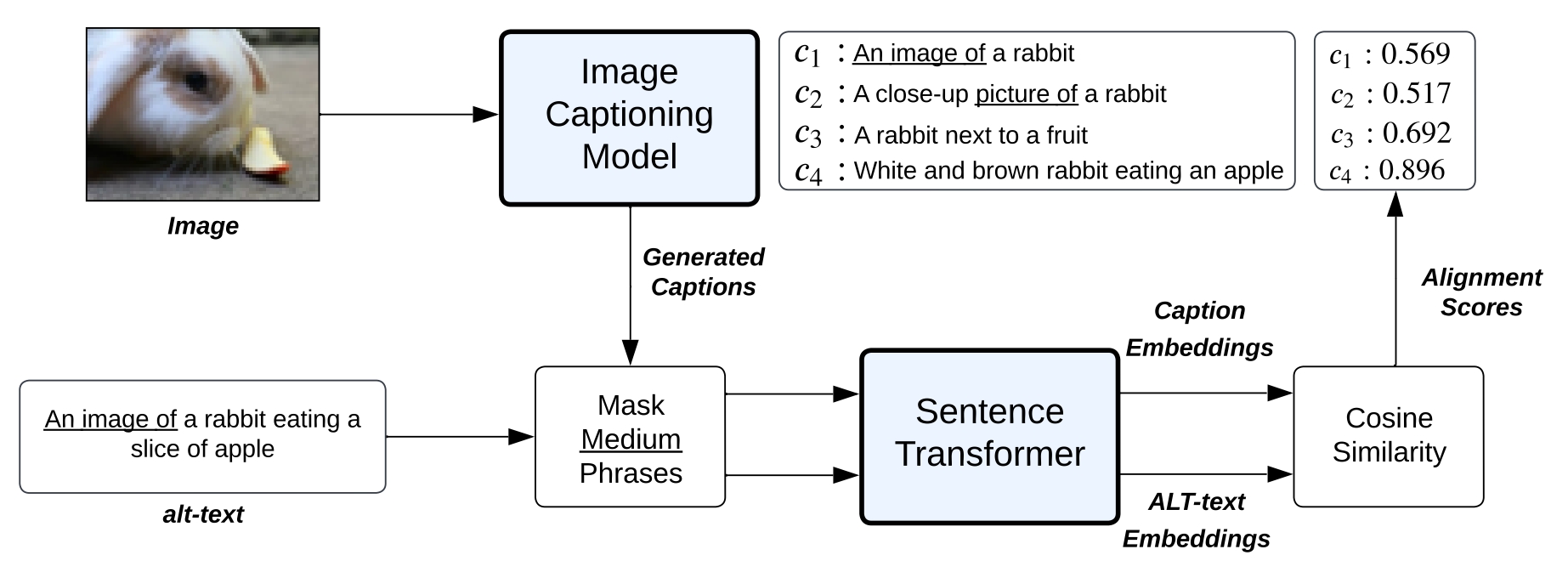
Vision-Language Models (VLMs) are pretrained on large, diverse, and noisy web-crawled datasets. This underscores the critical need for dataset pruning, as the quality of these datasets is strongly correlated with the performance of VLMs on downstream tasks. Using CLIPScore from a pretrained model to only train models using highly-aligned samples is one of the most successful methods for pruning. We argue that this approach suffers from multiple limitations including: false positives and negatives due to CLIP's pretraining on noisy labels. We propose a pruning signal, Sieve, that employs synthetic captions generated by image-captioning models pretrained on small, diverse, and well-aligned image-text pairs to evaluate the alignment of noisy image-text pairs. To bridge the gap between the limited diversity of generated captions and the high diversity of alternative text (alt-text), we estimate the semantic textual similarity in the embedding space of a language model pretrained on unlabeled text corpus. Using DataComp, a multimodal dataset filtering benchmark, when evaluating on 38 downstream tasks, our pruning approach, surpasses CLIPScore by 2.6\% and 1.7\% on medium and large scale respectively. In addition, on retrieval tasks, Sieve leads to a significant improvement of 2.7% and 4.5% on medium and large scale respectively.
PDF Abstract



 ImageNet
ImageNet
 MS COCO
MS COCO
