Single Shot Text Detector with Regional Attention
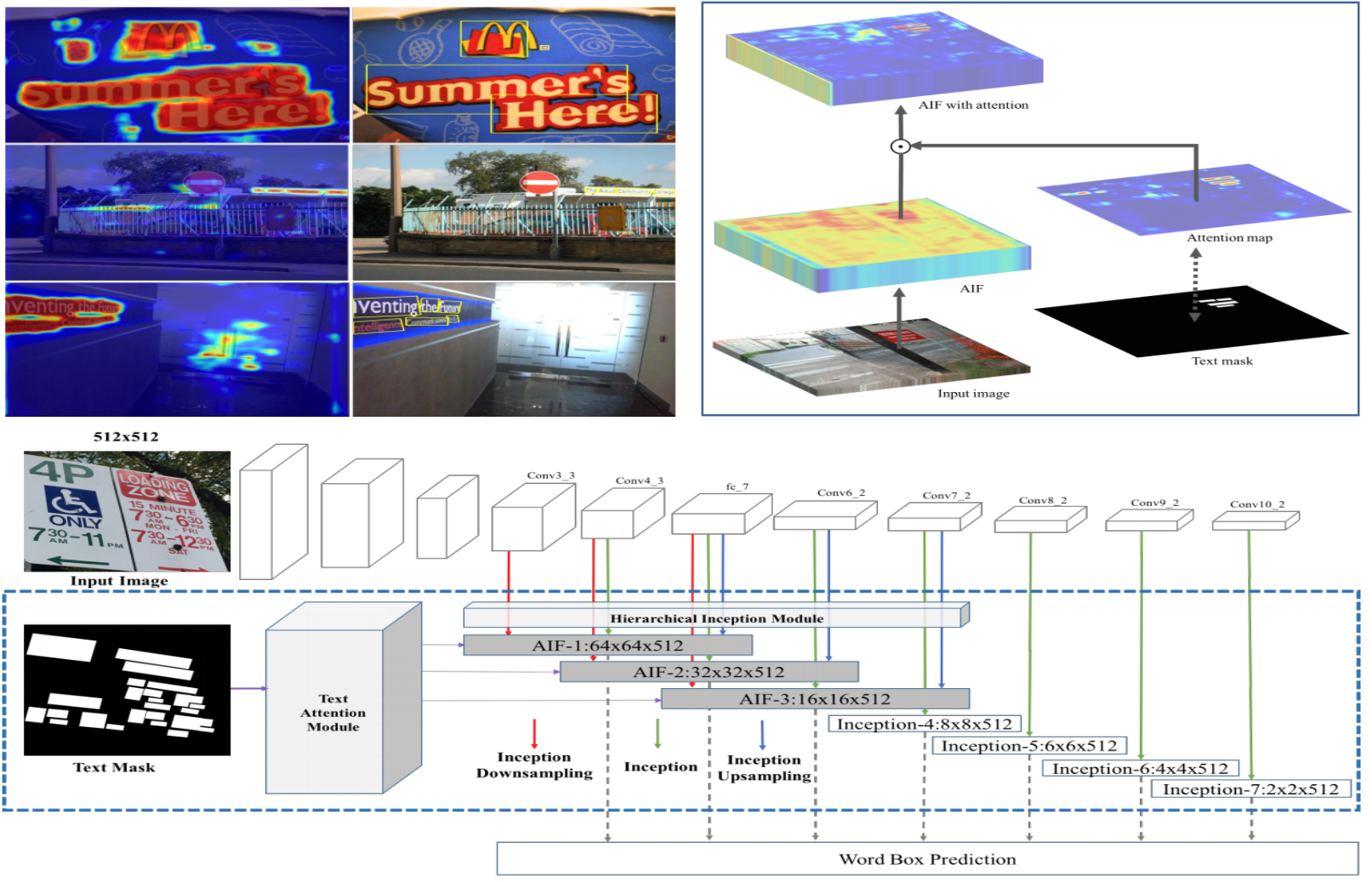
We present a novel single-shot text detector that directly outputs word-level bounding boxes in a natural image. We propose an attention mechanism which roughly identifies text regions via an automatically learned attentional map. This substantially suppresses background interference in the convolutional features, which is the key to producing accurate inference of words, particularly at extremely small sizes. This results in a single model that essentially works in a coarse-to-fine manner. It departs from recent FCN- based text detectors which cascade multiple FCN models to achieve an accurate prediction. Furthermore, we develop a hierarchical inception module which efficiently aggregates multi-scale inception features. This enhances local details, and also encodes strong context information, allow- ing the detector to work reliably on multi-scale and multi- orientation text with single-scale images. Our text detector achieves an F-measure of 77% on the ICDAR 2015 bench- mark, advancing the state-of-the-art results in [18, 28]. Demo is available at: http://sstd.whuang.org/.
PDF Abstract ICCV 2017 PDF ICCV 2017 Abstract
 ssd
ssd
 ICDAR 2013
ICDAR 2013
 COCO-Text
COCO-Text

