
Towards Better Accuracy-efficiency Trade-offs: Divide and Co-training
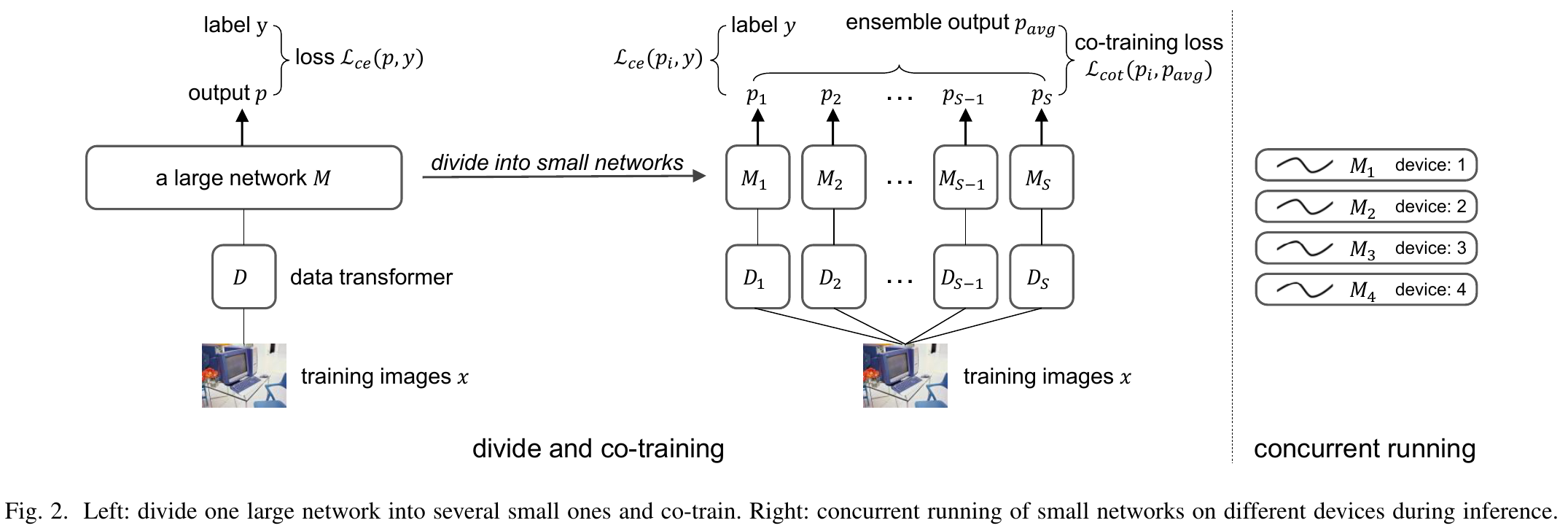
The width of a neural network matters since increasing the width will necessarily increase the model capacity. However, the performance of a network does not improve linearly with the width and soon gets saturated. In this case, we argue that increasing the number of networks (ensemble) can achieve better accuracy-efficiency trade-offs than purely increasing the width. To prove it, one large network is divided into several small ones regarding its parameters and regularization components. Each of these small networks has a fraction of the original one's parameters. We then train these small networks together and make them see various views of the same data to increase their diversity. During this co-training process, networks can also learn from each other. As a result, small networks can achieve better ensemble performance than the large one with few or no extra parameters or FLOPs, \ie, achieving better accuracy-efficiency trade-offs. Small networks can also achieve faster inference speed than the large one by concurrent running. All of the above shows that the number of networks is a new dimension of model scaling. We validate our argument with 8 different neural architectures on common benchmarks through extensive experiments. The code is available at \url{https://github.com/FreeformRobotics/Divide-and-Co-training}.
PDF AbstractCode

Tasks

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 ssd
ssd

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Image Classification | CIFAR-10 | PyramidNet-272, S=4 | Percentage correct | 98.71 | # 26 | ||
| PARAMS | 32.6M | # 219 | |||||
| Image Classification | CIFAR-10 | Shake-Shake 26 2x96d, S=4 | Percentage correct | 98.31 | # 39 | ||
| PARAMS | 26.3M | # 217 | |||||
| Image Classification | CIFAR-10 | WRN-28-10, S=4 | Percentage correct | 98.32 | # 38 | ||
| PARAMS | 36.7M | # 227 | |||||
| Image Classification | CIFAR-10 | WRN-40-10, S=4 | Percentage correct | 98.38 | # 37 | ||
| PARAMS | 55.9M | # 231 | |||||
| Image Classification | CIFAR-100 | DenseNet-BC-190, S=4 | Percentage correct | 87.44 | # 46 | ||
| PARAMS | 26.3M | # 193 | |||||
| Image Classification | CIFAR-100 | PyramidNet-272, S=4 | Percentage correct | 89.46 | # 31 | ||
| PARAMS | 32.8M | # 194 | |||||
| Image Classification | CIFAR-100 | WRN-28-10, S=4 | Percentage correct | 85.74 | # 59 | ||
| Image Classification | CIFAR-100 | WRN-40-10, S=4 | Percentage correct | 86.90 | # 49 | ||
| Image Classification | ImageNet | SE-ResNeXt-101, 64x4d, S=2(320px) | Top 1 Accuracy | 83.6% | # 378 | ||
| Number of params | 98M | # 859 | |||||
| GFLOPs | 38.2 | # 410 | |||||
| Image Classification | ImageNet | ResNeXt-101, 64x4d, S=2(224px) | Top 1 Accuracy | 82.13% | # 523 | ||
| Number of params | 88.6M | # 842 | |||||
| GFLOPs | 18.8 | # 361 | |||||
| Image Classification | ImageNet | SE-ResNeXt-101, 64x4d, S=2(416px) | Top 1 Accuracy | 83.34% | # 402 | ||
| Number of params | 98M | # 859 | |||||
| Hardware Burden | None | # 1 | |||||
| Operations per network pass | None | # 1 | |||||
| GFLOPs | 61.1 | # 433 |
