Steerers: A framework for rotation equivariant keypoint descriptors
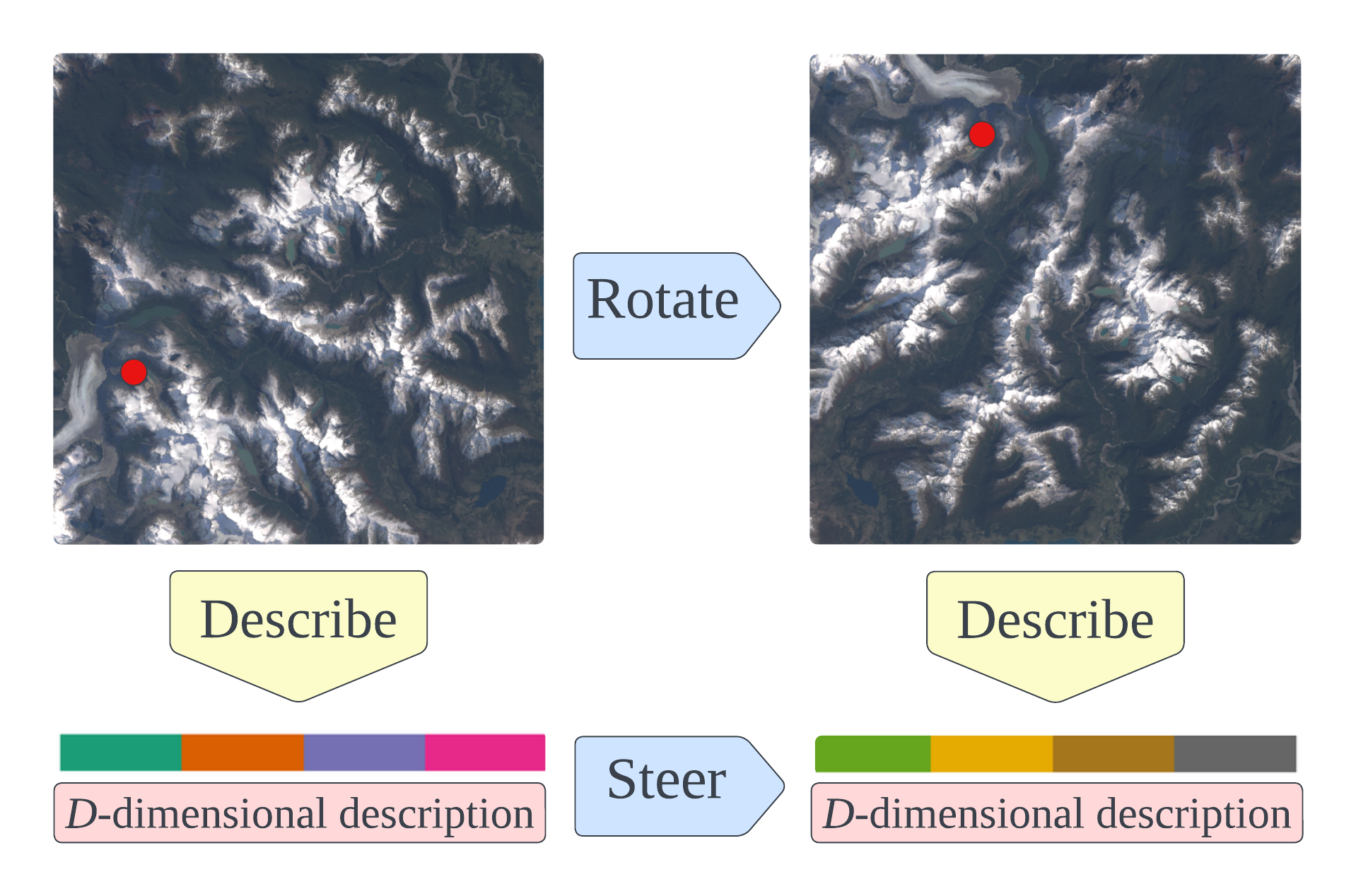
Image keypoint descriptions that are discriminative and matchable over large changes in viewpoint are vital for 3D reconstruction. However, descriptions output by learned descriptors are typically not robust to camera rotation. While they can be made more robust by, e.g., data augmentation, this degrades performance on upright images. Another approach is test-time augmentation, which incurs a significant increase in runtime. Instead, we learn a linear transform in description space that encodes rotations of the input image. We call this linear transform a steerer since it allows us to transform the descriptions as if the image was rotated. From representation theory, we know all possible steerers for the rotation group. Steerers can be optimized (A) given a fixed descriptor, (B) jointly with a descriptor or (C) we can optimize a descriptor given a fixed steerer. We perform experiments in these three settings and obtain state-of-the-art results on the rotation invariant image matching benchmarks AIMS and Roto-360. We publish code and model weights at https://github.com/georg-bn/rotation-steerers.
PDF Abstract


