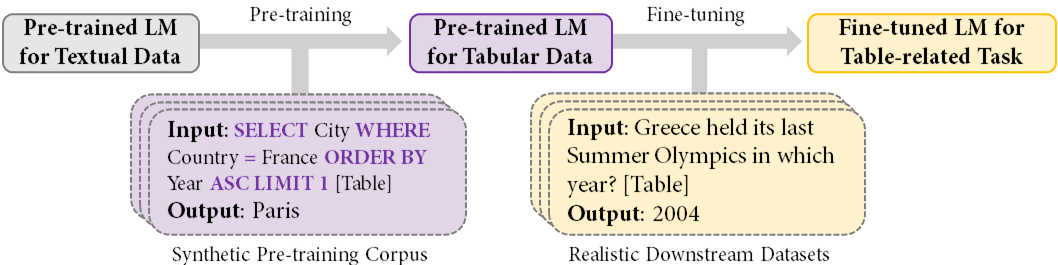
TAPEX: Table Pre-training via Learning a Neural SQL Executor
Recent progress in language model pre-training has achieved a great success via leveraging large-scale unstructured textual data. However, it is still a challenge to apply pre-training on structured tabular data due to the absence of large-scale high-quality tabular data. In this paper, we propose TAPEX to show that table pre-training can be achieved by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries and their execution outputs. TAPEX addresses the data scarcity challenge via guiding the language model to mimic a SQL executor on the diverse, large-scale and high-quality synthetic corpus. We evaluate TAPEX on four benchmark datasets. Experimental results demonstrate that TAPEX outperforms previous table pre-training approaches by a large margin and achieves new state-of-the-art results on all of them. This includes the improvements on the weakly-supervised WikiSQL denotation accuracy to 89.5% (+2.3%), the WikiTableQuestions denotation accuracy to 57.5% (+4.8%), the SQA denotation accuracy to 74.5% (+3.5%), and the TabFact accuracy to 84.2% (+3.2%). To our knowledge, this is the first work to exploit table pre-training via synthetic executable programs and to achieve new state-of-the-art results on various downstream tasks. Our code can be found at https://github.com/microsoft/Table-Pretraining.
PDF Abstract ICLR 2022 PDF ICLR 2022 Abstract


Datasets
 WikiSQL
WikiSQL
 TabFact
TabFact
 WikiTableQuestions
WikiTableQuestions
 SQA
SQA
Results from the Paper
 Ranked #1 on
Semantic Parsing
on WikiSQL
(Denotation accuracy (test) metric)
Ranked #1 on
Semantic Parsing
on WikiSQL
(Denotation accuracy (test) metric)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Semantic Parsing | SQA | TAPEX-Large | Denotation Accuracy | 74.5 | # 1 | |
| Table-based Fact Verification | TabFact | TAPEX-Large | Test | 84.2 | # 6 | |
| Val | 84.6 | # 2 | ||||
| Semantic Parsing | WikiSQL | TAPEX-Large (weak supervision) | Denotation accuracy (test) | 89.5 | # 1 | |
| Semantic Parsing | WikiTableQuestions | TAPEX-Large | Accuracy (Dev) | 57.0 | # 6 | |
| Accuracy (Test) | 57.5 | # 9 |
