TartanVO: A Generalizable Learning-based VO
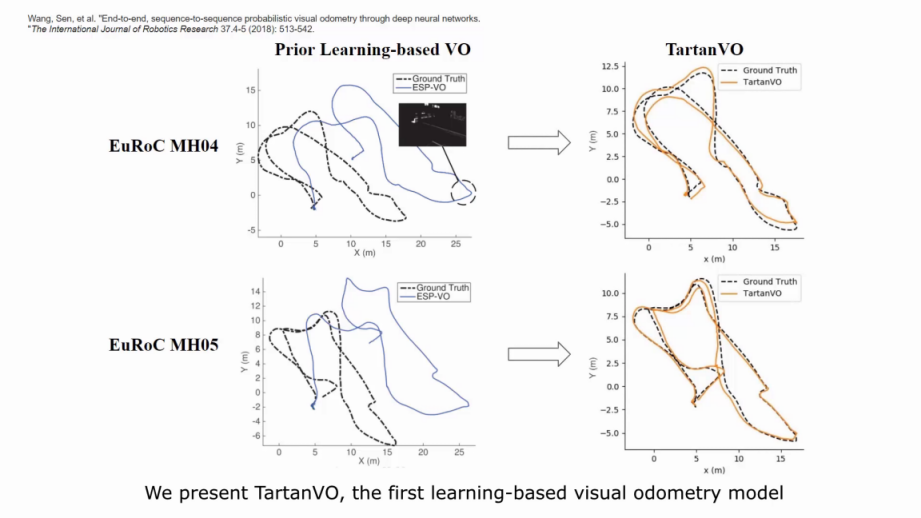
We present the first learning-based visual odometry (VO) model, which generalizes to multiple datasets and real-world scenarios and outperforms geometry-based methods in challenging scenes. We achieve this by leveraging the SLAM dataset TartanAir, which provides a large amount of diverse synthetic data in challenging environments. Furthermore, to make our VO model generalize across datasets, we propose an up-to-scale loss function and incorporate the camera intrinsic parameters into the model. Experiments show that a single model, TartanVO, trained only on synthetic data, without any finetuning, can be generalized to real-world datasets such as KITTI and EuRoC, demonstrating significant advantages over the geometry-based methods on challenging trajectories. Our code is available at https://github.com/castacks/tartanvo.
PDF Abstract

