Understanding The Robustness in Vision Transformers
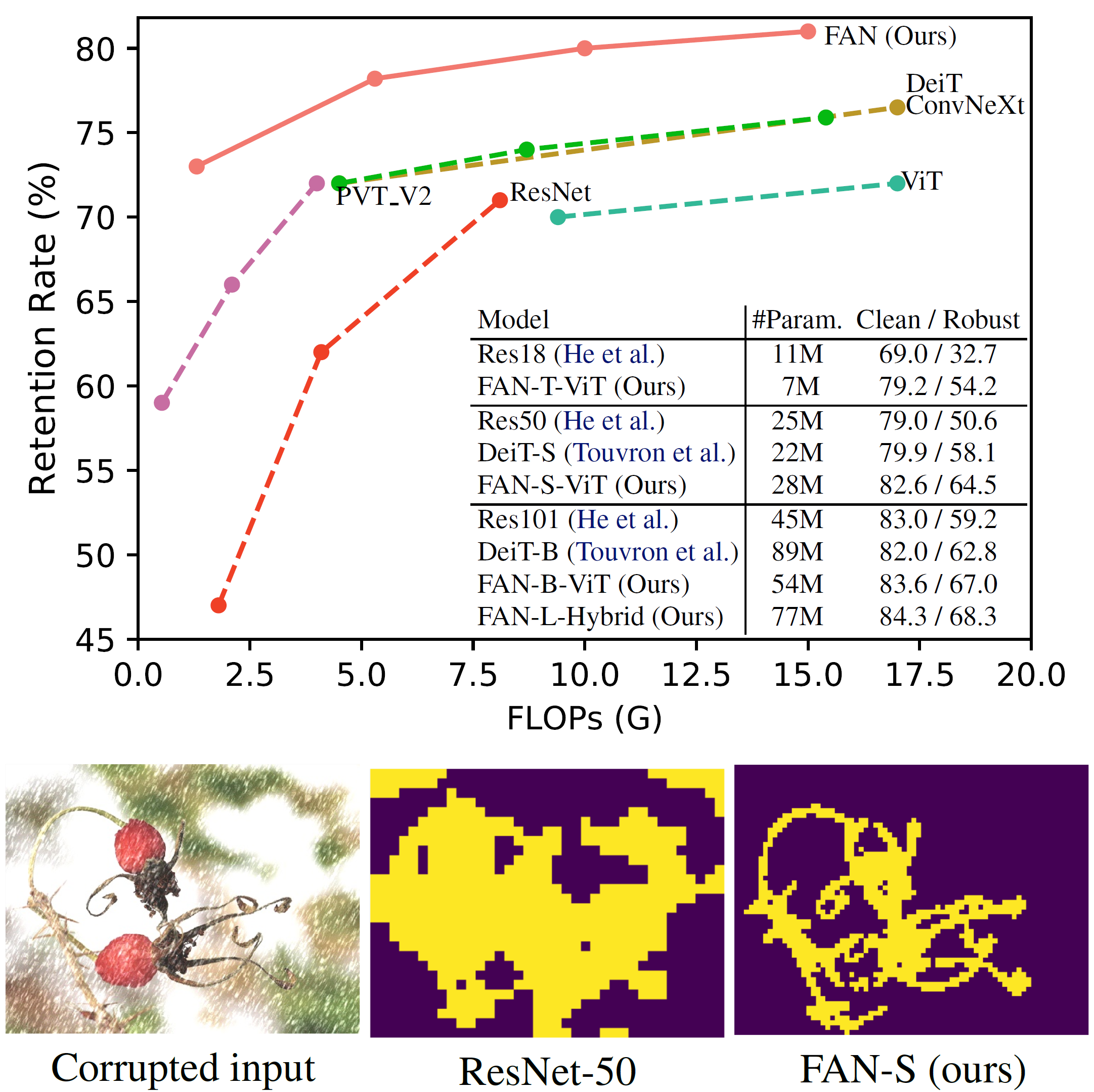
Recent studies show that Vision Transformers(ViTs) exhibit strong robustness against various corruptions. Although this property is partly attributed to the self-attention mechanism, there is still a lack of systematic understanding. In this paper, we examine the role of self-attention in learning robust representations. Our study is motivated by the intriguing properties of the emerging visual grouping in Vision Transformers, which indicates that self-attention may promote robustness through improved mid-level representations. We further propose a family of fully attentional networks (FANs) that strengthen this capability by incorporating an attentional channel processing design. We validate the design comprehensively on various hierarchical backbones. Our model achieves a state-of-the-art 87.1% accuracy and 35.8% mCE on ImageNet-1k and ImageNet-C with 76.8M parameters. We also demonstrate state-of-the-art accuracy and robustness in two downstream tasks: semantic segmentation and object detection. Code is available at: https://github.com/NVlabs/FAN.
PDF AbstractCode





 ImageNet
ImageNet
 MS COCO
MS COCO
 Cityscapes
Cityscapes
 ImageNet-C
ImageNet-C
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 DensePASS
DensePASS
Results from the Paper
 Ranked #4 on
Domain Generalization
on ImageNet-R
(using extra training data)
Ranked #4 on
Domain Generalization
on ImageNet-R
(using extra training data)
