Unified Multimodal Model with Unlikelihood Training for Visual Dialog
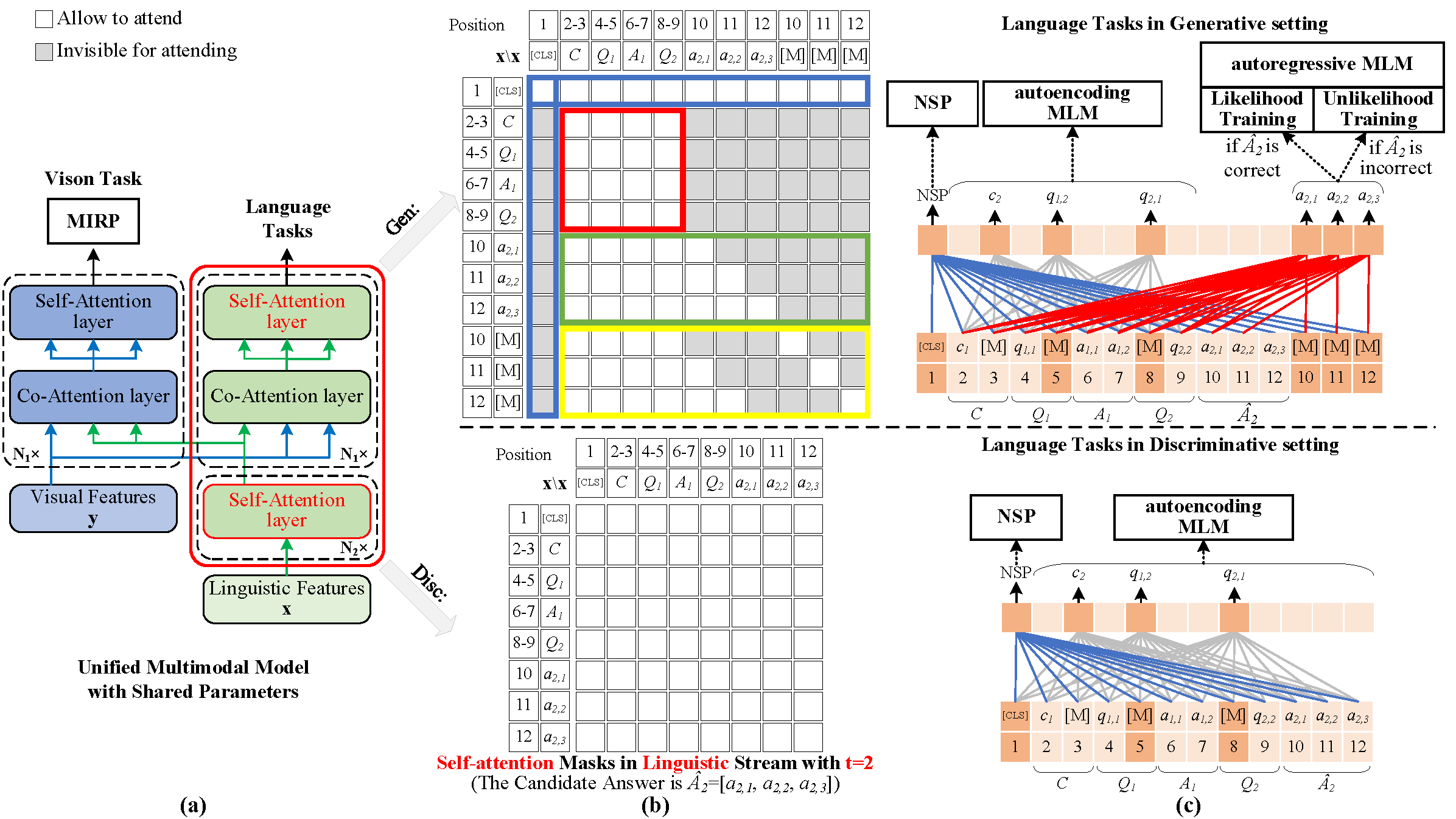
The task of visual dialog requires a multimodal chatbot to answer sequential questions from humans about image content. Prior work performs the standard likelihood training for answer generation on the positive instances (involving correct answers). However, the likelihood objective often leads to frequent and dull outputs and fails to exploit the useful knowledge from negative instances (involving incorrect answers). In this paper, we propose a Unified Multimodal Model with UnLikelihood Training, named UniMM-UL, to tackle this problem. First, to improve visual dialog understanding and generation by multi-task learning, our model extends ViLBERT from only supporting answer discrimination to holding both answer discrimination and answer generation seamlessly by different attention masks. Specifically, in order to make the original discriminative model compatible with answer generation, we design novel generative attention masks to implement the autoregressive Masked Language Modeling (autoregressive MLM) task. And to attenuate the adverse effects of the likelihood objective, we exploit unlikelihood training on negative instances to make the model less likely to generate incorrect answers. Then, to utilize dense annotations, we adopt different fine-tuning methods for both generating and discriminating answers, rather than just for discriminating answers as in the prior work. Finally, on the VisDial dataset, our model achieves the best generative results (69.23 NDCG score). And our model also yields comparable discriminative results with the state-of-the-art in both single-model and ensemble settings (75.92 and 76.17 NDCG scores).
PDF Abstract





 VisDial
VisDial
