Unsupervised speech representation learning using WaveNet autoencoders
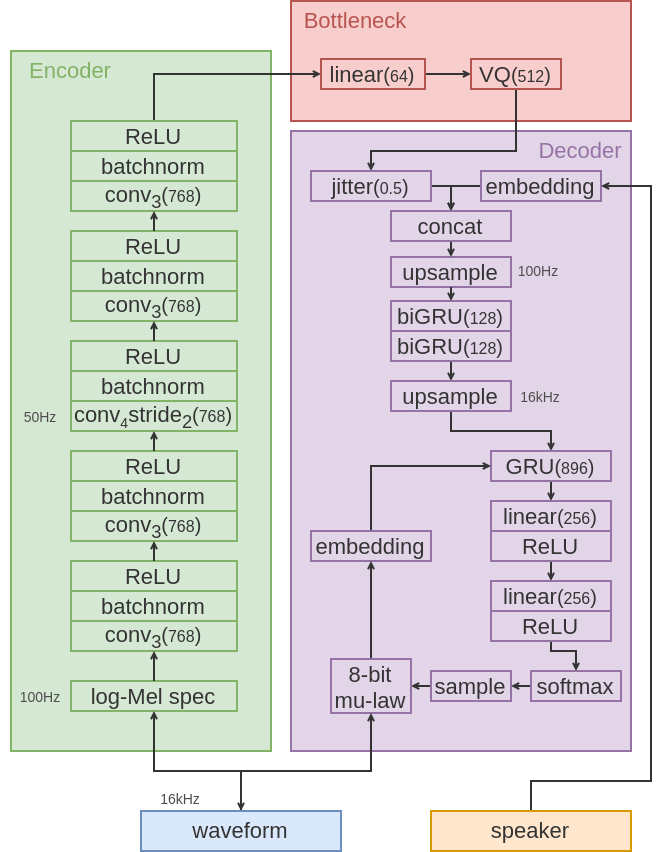
We consider the task of unsupervised extraction of meaningful latent representations of speech by applying autoencoding neural networks to speech waveforms. The goal is to learn a representation able to capture high level semantic content from the signal, e.g.\ phoneme identities, while being invariant to confounding low level details in the signal such as the underlying pitch contour or background noise. Since the learned representation is tuned to contain only phonetic content, we resort to using a high capacity WaveNet decoder to infer information discarded by the encoder from previous samples. Moreover, the behavior of autoencoder models depends on the kind of constraint that is applied to the latent representation. We compare three variants: a simple dimensionality reduction bottleneck, a Gaussian Variational Autoencoder (VAE), and a discrete Vector Quantized VAE (VQ-VAE). We analyze the quality of learned representations in terms of speaker independence, the ability to predict phonetic content, and the ability to accurately reconstruct individual spectrogram frames. Moreover, for discrete encodings extracted using the VQ-VAE, we measure the ease of mapping them to phonemes. We introduce a regularization scheme that forces the representations to focus on the phonetic content of the utterance and report performance comparable with the top entries in the ZeroSpeech 2017 unsupervised acoustic unit discovery task.
PDF Abstract




 LibriSpeech
LibriSpeech
