Visual Parser: Representing Part-whole Hierarchies with Transformers
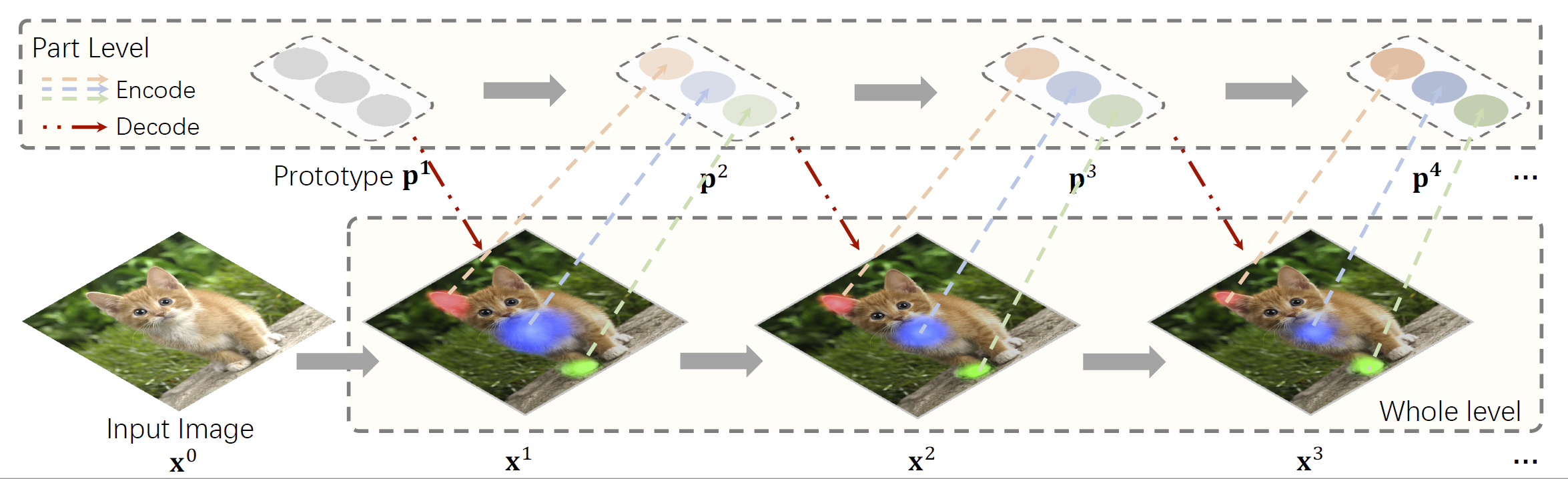
Human vision is able to capture the part-whole hierarchical information from the entire scene. This paper presents the Visual Parser (ViP) that explicitly constructs such a hierarchy with transformers. ViP divides visual representations into two levels, the part level and the whole level. Information of each part represents a combination of several independent vectors within the whole. To model the representations of the two levels, we first encode the information from the whole into part vectors through an attention mechanism, then decode the global information within the part vectors back into the whole representation. By iteratively parsing the two levels with the proposed encoder-decoder interaction, the model can gradually refine the features on both levels. Experimental results demonstrate that ViP can achieve very competitive performance on three major tasks e.g. classification, detection and instance segmentation. In particular, it can surpass the previous state-of-the-art CNN backbones by a large margin on object detection. The tiny model of the ViP family with $7.2\times$ fewer parameters and $10.9\times$ fewer FLOPS can perform comparably with the largest model ResNeXt-101-64$\times$4d of ResNe(X)t family. Visualization results also demonstrate that the learnt parts are highly informative of the predicting class, making ViP more explainable than previous fundamental architectures. Code is available at https://github.com/kevin-ssy/ViP.
PDF Abstract





 ImageNet
ImageNet
 MS COCO
MS COCO

