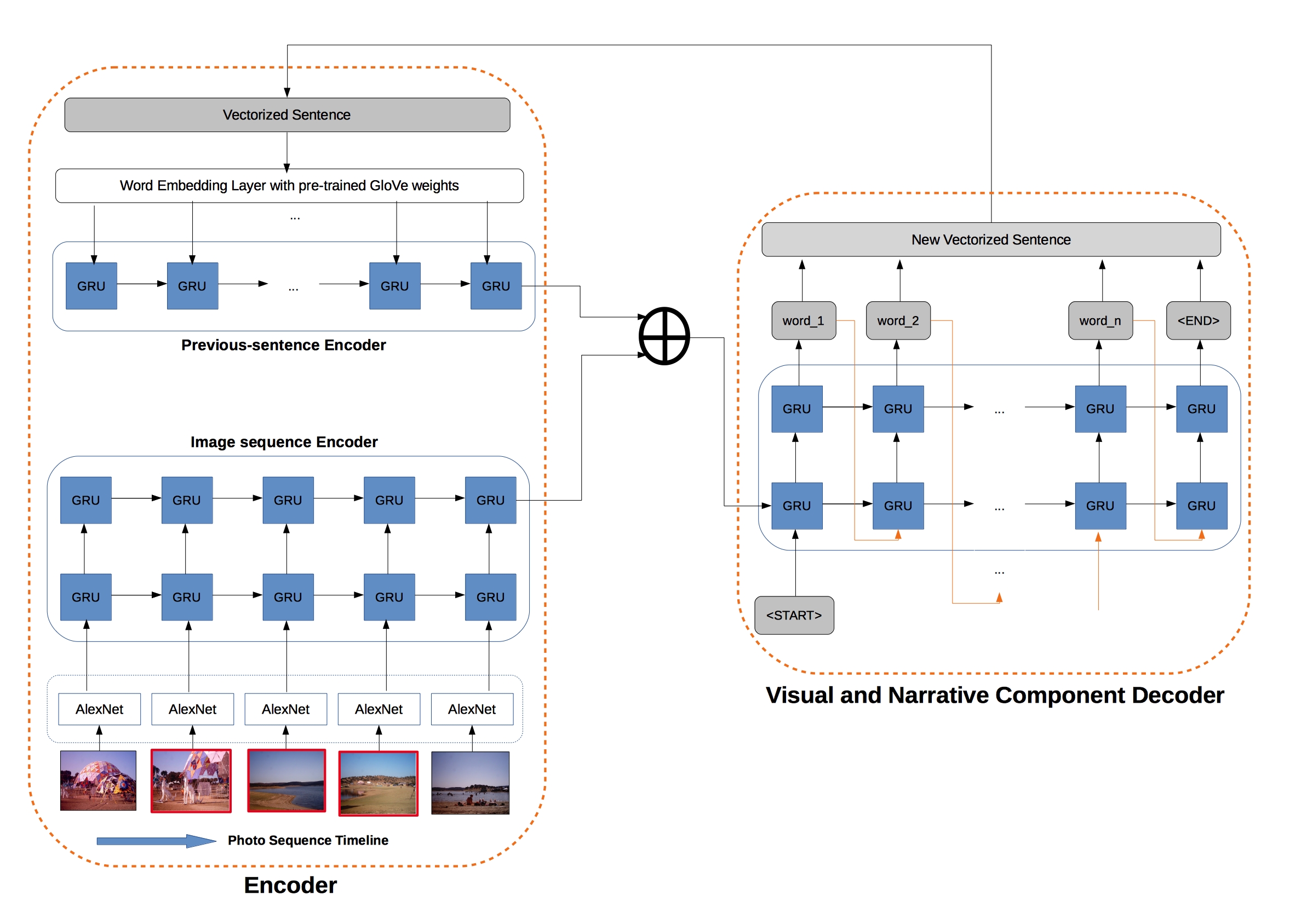
Visual Storytelling
We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The first release of this dataset, SIND v.1, includes 81,743 unique photos in 20,211 sequences, aligned to both descriptive (caption) and story language. We establish several strong baselines for the storytelling task, and motivate an automatic metric to benchmark progress. Modelling concrete description as well as figurative and social language, as provided in this dataset and the storytelling task, has the potential to move artificial intelligence from basic understandings of typical visual scenes towards more and more human-like understanding of grounded event structure and subjective expression.
PDF Abstract NAACL 2016 PDF NAACL 2016 Abstract


 VIST
VIST
 MS COCO
MS COCO
 Flickr30k
Flickr30k
