Visually Grounded Continual Learning of Compositional Phrases
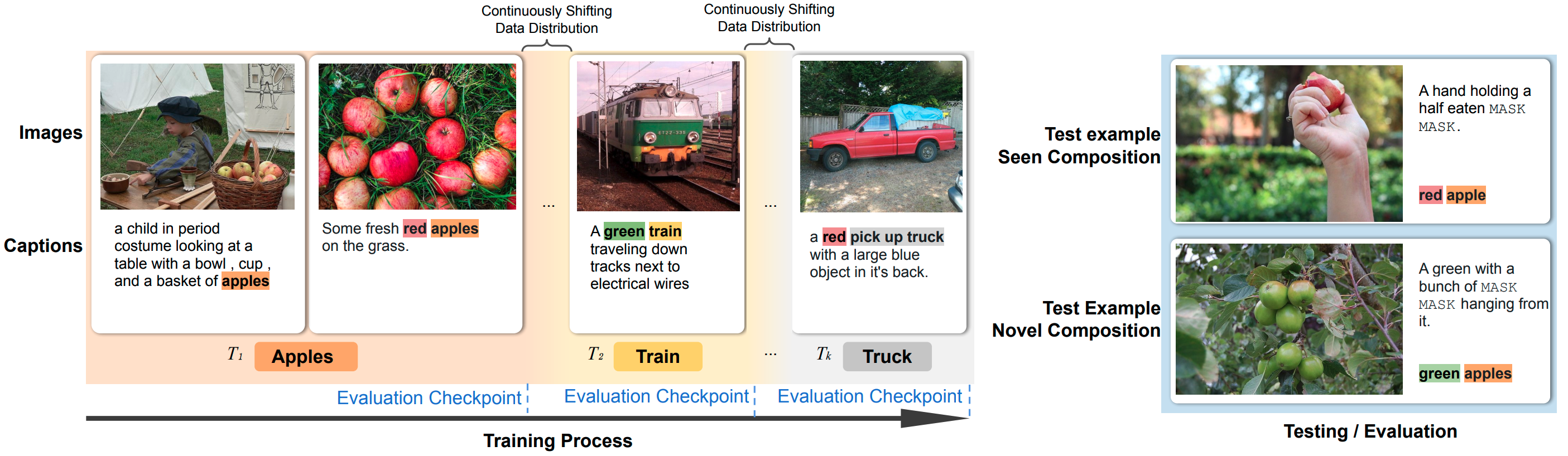
Humans acquire language continually with much more limited access to data samples at a time, as compared to contemporary NLP systems. To study this human-like language acquisition ability, we present VisCOLL, a visually grounded language learning task, which simulates the continual acquisition of compositional phrases from streaming visual scenes. In the task, models are trained on a paired image-caption stream which has shifting object distribution; while being constantly evaluated by a visually-grounded masked language prediction task on held-out test sets. VisCOLL compounds the challenges of continual learning (i.e., learning from continuously shifting data distribution) and compositional generalization (i.e., generalizing to novel compositions). To facilitate research on VisCOLL, we construct two datasets, COCO-shift and Flickr-shift, and benchmark them using different continual learning methods. Results reveal that SoTA continual learning approaches provide little to no improvements on VisCOLL, since storing examples of all possible compositions is infeasible. We conduct further ablations and analysis to guide future work.
PDF Abstract EMNLP 2020 PDF EMNLP 2020 Abstract



 MS COCO
MS COCO
 Flickr30k
Flickr30k
