Search Results for author:
Found 24 papers, 6 papers with code
Duality induced by an embedding structure of determinantal point process
This paper investigates the information geometrical structure of a determinantal point process (DPP).
A Short Survey on Importance Weighting for Machine Learning
Importance weighting is a fundamental procedure in statistics and machine learning that weights the objective function or probability distribution based on the importance of the instance in some sense.
Scalable Counterfactual Distribution Estimation in Multivariate Causal Models
We consider the problem of estimating the counterfactual joint distribution of multiple quantities of interests (e. g., outcomes) in a multivariate causal model extended from the classical difference-in-difference design.

Information Geometrically Generalized Covariate Shift Adaptation
In particular, the phenomenon that the marginal distribution of the data changes is called covariate shift, one of the most important research topics in machine learning.
Active Learning by Query by Committee with Robust Divergences
In this paper, the measure of disagreement is defined by the Bregman divergence, which includes the Kullback--Leibler divergence as an instance, and the dual $\gamma$-power divergence.
Unsupervised Domain Adaptation for Extra Features in the Target Domain Using Optimal Transport
In this paper, it is assumed that common features exist in both domains and that extra (new additional) features are observed in the target domain; hence, the dimensionality of the target domain is higher than that of the source domain.
Gaussian Process Koopman Mode Decomposition
In this paper, we propose a nonlinear probabilistic generative model of Koopman mode decomposition based on an unsupervised Gaussian process.
Geometry of EM and related iterative algorithms
The Expectation--Maximization (EM) algorithm is a simple meta-algorithm that has been used for many years as a methodology for statistical inference when there are missing measurements in the observed data or when the data is composed of observables and unobservables.
Gradual Domain Adaptation via Normalizing Flows
In previous work, it is assumed that the number of intermediate domains is large and the distance between adjacent domains is small; hence, the gradual domain adaptation algorithm, involving self-training with unlabeled datasets, is applicable.
Information Geometry of Dropout Training
Dropout is one of the most popular regularization techniques in neural network training.
One-bit Submission for Locally Private Quasi-MLE: Its Asymptotic Normality and Limitation
Local differential privacy~(LDP) is an information-theoretic privacy definition suitable for statistical surveys that involve an untrusted data curator.
Cost-effective Framework for Gradual Domain Adaptation with Multifidelity
Practically, the cost of samples in intermediate domains will vary, and it is natural to consider that the closer an intermediate domain is to the target domain, the higher the cost of obtaining samples from the intermediate domain is.

Fast symplectic integrator for Nesterov-type acceleration method
In this paper, explicit stable integrators based on symplectic and contact geometries are proposed for a non-autonomous ordinarily differential equation (ODE) found in improving convergence rate of Nesterov's accelerated gradient method.
Stopping Criterion for Active Learning Based on Error Stability
Active learning is a framework for supervised learning to improve the predictive performance by adaptively annotating a small number of samples.
$α$-Geodesical Skew Divergence
The asymmetric skew divergence smooths one of the distributions by mixing it, to a degree determined by the parameter $\lambda$, with the other distribution.
Active Learning: Problem Settings and Recent Developments
In supervised learning, acquiring labeled training data for a predictive model can be very costly, but acquiring a large amount of unlabeled data is often quite easy.
Modal Principal Component Analysis
Thus, this study proposes a modal principal component analysis (MPCA), which is a robust PCA method based on mode estimation.

Stopping criterion for active learning based on deterministic generalization bounds
Active learning is a framework in which the learning machine can select the samples to be used for training.
Fast and robust multiplane single molecule localization microscopy using deep neural network
Single molecule localization microscopy is widely used in biological research for measuring the nanostructures of samples smaller than the diffraction limit.
On a convergence property of a geometrical algorithm for statistical manifolds
In this paper, we examine a geometrical projection algorithm for statistical inference.
Bayesian Optimization for Multi-objective Optimization and Multi-point Search
It is difficult to analytically maximize the acquisition function as the computational cost is prohibitive even when approximate calculations such as sampling approximation are performed; therefore, we propose an accurate and computationally efficient method for estimating gradient of the acquisition function, and develop an algorithm for Bayesian optimization with multi-objective and multi-point search.
Classification of volcanic ash particles using a convolutional neural network and probability
Using the trained network, we classified ash particles composed of multiple basal shapes based on the output of the network, which can be interpreted as a mixing ratio of the four basal shapes.


Double Sparse Multi-Frame Image Super Resolution
A large number of image super resolution algorithms based on the sparse coding are proposed, and some algorithms realize the multi-frame super resolution.

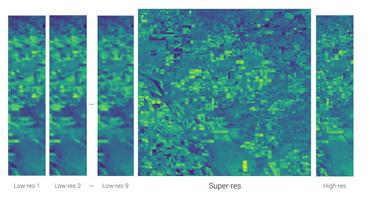
Sparse Coding Approach for Multi-Frame Image Super Resolution
Relative displacements of small patches of observed low-resolution images are accurately estimated by a computationally efficient block matching method.
