 Meta-Learning Algorithms
Meta-Learning Algorithms
Meta Reward Learning
Introduced by Agarwal et al. in Learning to Generalize from Sparse and Underspecified RewardsMeta Reward Learning (MeRL) is a meta-learning method for the problem of learning from sparse and underspecified rewards. For example, an agent receives a complex input, such as a natural language instruction, and needs to generate a complex response, such as an action sequence, while only receiving binary success-failure feedback. The key insight of MeRL in dealing with underspecified rewards is that spurious trajectories and programs that achieve accidental success are detrimental to the agent's generalization performance. For example, an agent might be able to solve a specific instance of the maze problem above. However, if it learns to perform spurious actions during training, it is likely to fail when provided with unseen instructions. To mitigate this issue, MeRL optimizes a more refined auxiliary reward function, which can differentiate between accidental and purposeful success based on features of action trajectories. The auxiliary reward is optimized by maximizing the trained agent's performance on a hold-out validation set via meta learning.
Source: Learning to Generalize from Sparse and Underspecified Rewards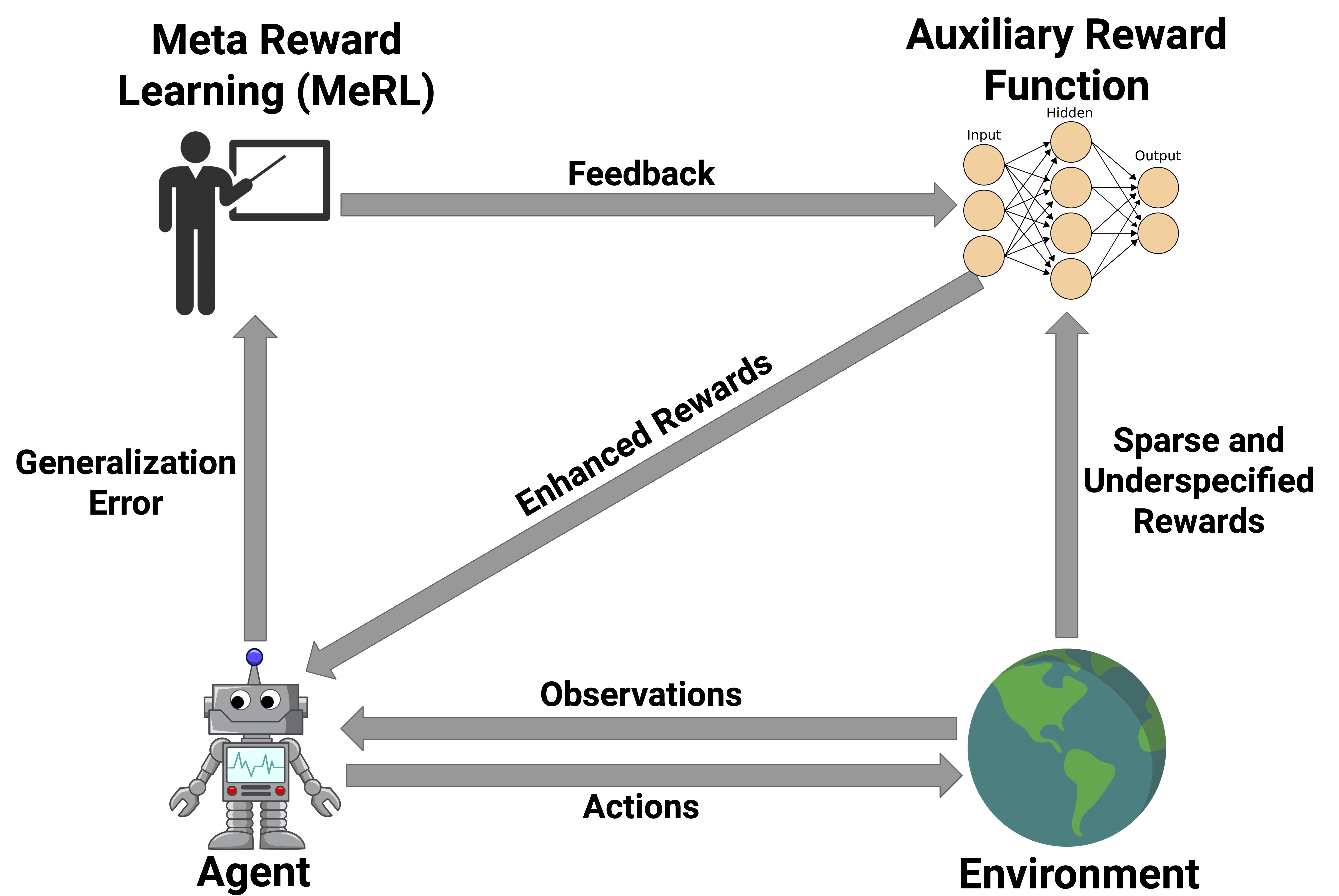
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Action Segmentation | 3 | 15.79% |
| Reinforcement Learning (RL) | 2 | 10.53% |
| Clinical Knowledge | 1 | 5.26% |
| ECG Classification | 1 | 5.26% |
| Prompt Engineering | 1 | 5.26% |
| Self-Supervised Learning | 1 | 5.26% |
| Zero-Shot Learning | 1 | 5.26% |
| Continuous Control | 1 | 5.26% |
| Optical Flow Estimation | 1 | 5.26% |
 MAML
MAML
