Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
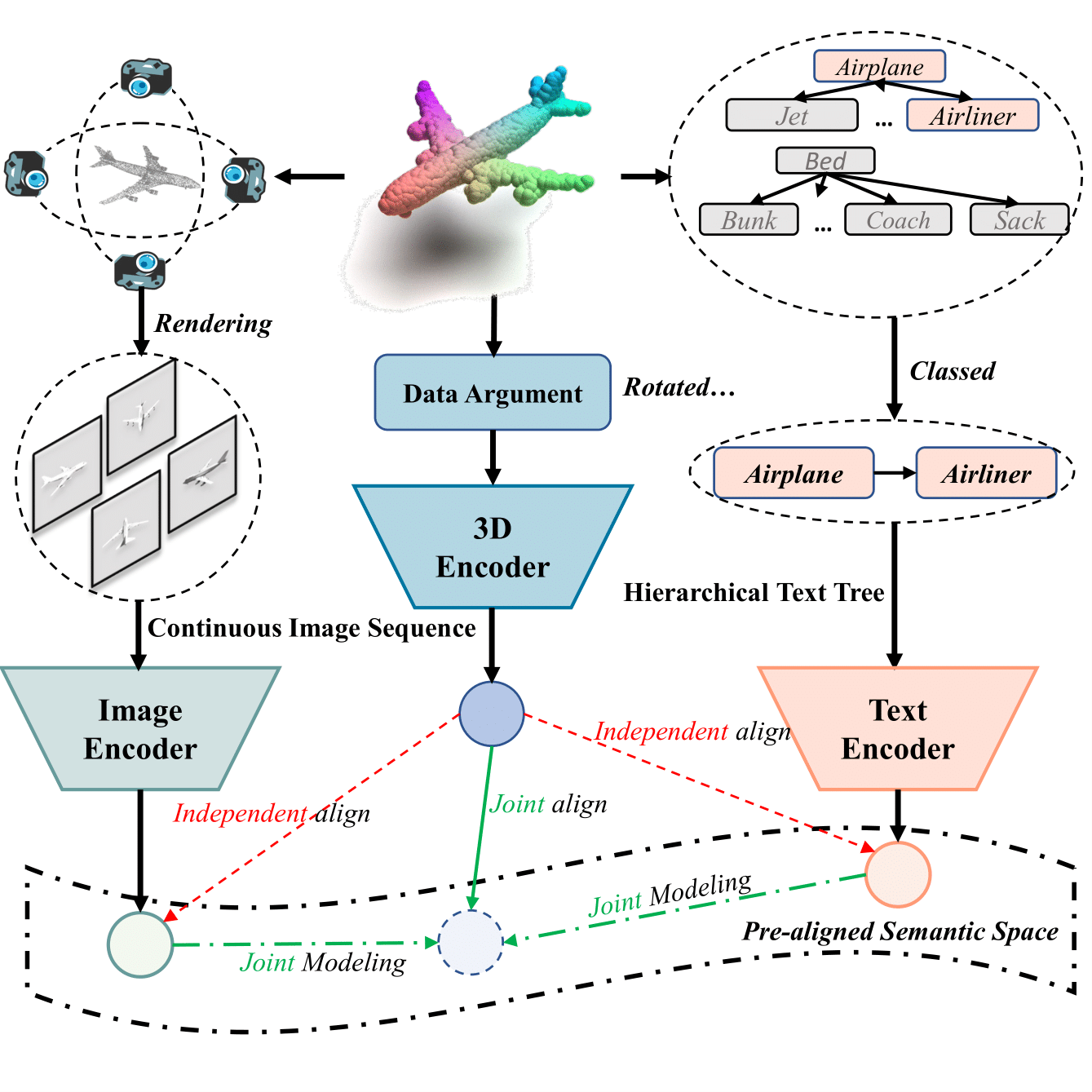
In recent years, 3D understanding has turned to 2D vision-language pre-trained models to overcome data scarcity challenges. However, existing methods simply transfer 2D alignment strategies, aligning 3D representations with single-view 2D images and coarse-grained parent category text. These approaches introduce information degradation and insufficient synergy issues, leading to performance loss. Information degradation arises from overlooking the fact that a 3D representation should be equivalent to a series of multi-view images and more fine-grained subcategory text. Insufficient synergy neglects the idea that a robust 3D representation should align with the joint vision-language space, rather than independently aligning with each modality. In this paper, we propose a multi-view joint modality modeling approach, termed JM3D, to obtain a unified representation for point cloud, text, and image. Specifically, a novel Structured Multimodal Organizer (SMO) is proposed to address the information degradation issue, which introduces contiguous multi-view images and hierarchical text to enrich the representation of vision and language modalities. A Joint Multi-modal Alignment (JMA) is designed to tackle the insufficient synergy problem, which models the joint modality by incorporating language knowledge into the visual modality. Extensive experiments on ModelNet40 and ScanObjectNN demonstrate the effectiveness of our proposed method, JM3D, which achieves state-of-the-art performance in zero-shot 3D classification. JM3D outperforms ULIP by approximately 4.3% on PointMLP and achieves an improvement of up to 6.5% accuracy on PointNet++ in top-1 accuracy for zero-shot 3D classification on ModelNet40. The source code and trained models for all our experiments are publicly available at https://github.com/Mr-Neko/JM3D.
PDF Abstract




 ShapeNet
ShapeNet
 ModelNet
ModelNet
 ScanObjectNN
ScanObjectNN

