Cap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
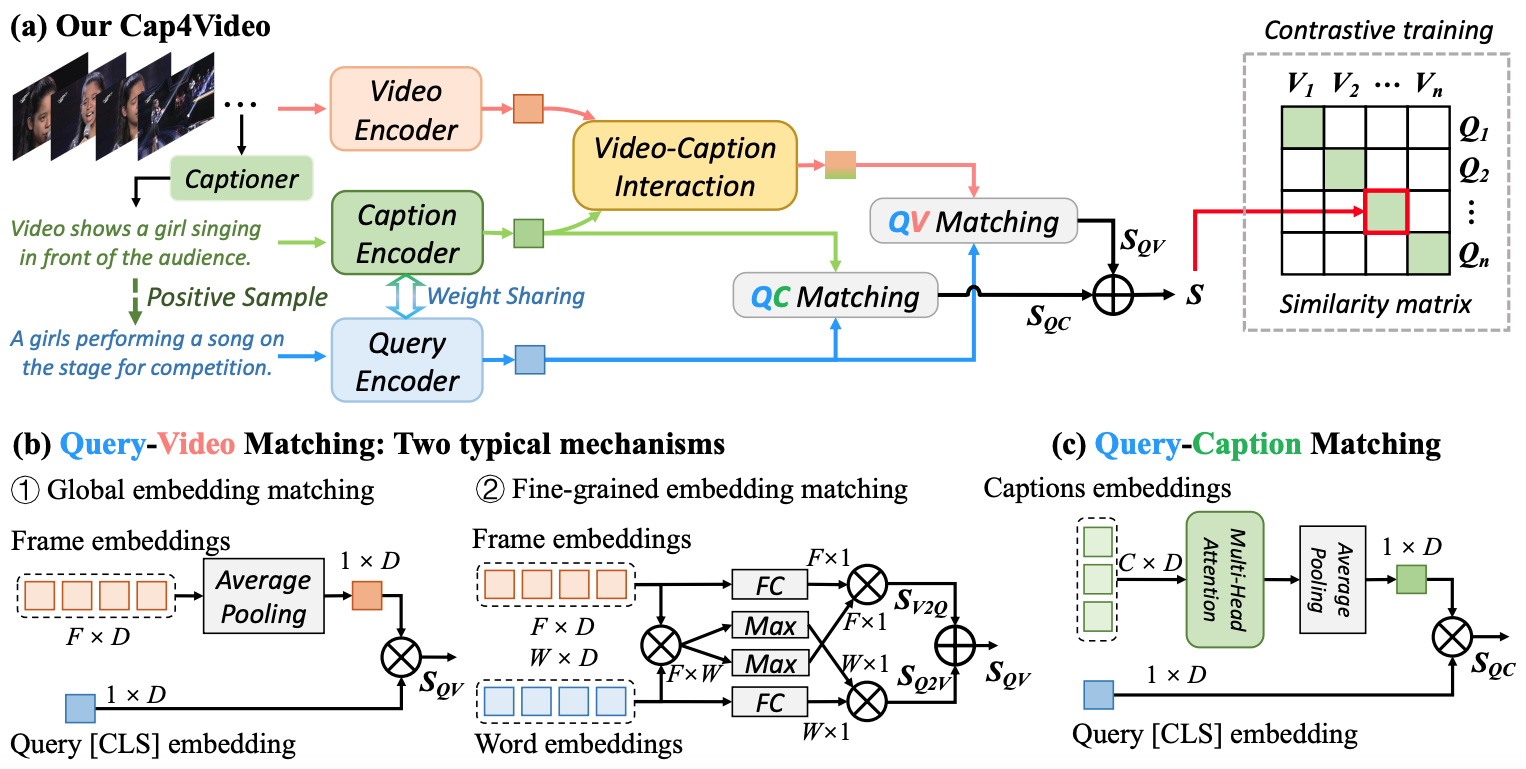
Most existing text-video retrieval methods focus on cross-modal matching between the visual content of videos and textual query sentences. However, in real-world scenarios, online videos are often accompanied by relevant text information such as titles, tags, and even subtitles, which can be utilized to match textual queries. This insight has motivated us to propose a novel approach to text-video retrieval, where we directly generate associated captions from videos using zero-shot video captioning with knowledge from web-scale pre-trained models (e.g., CLIP and GPT-2). Given the generated captions, a natural question arises: what benefits do they bring to text-video retrieval? To answer this, we introduce Cap4Video, a new framework that leverages captions in three ways: i) Input data: video-caption pairs can augment the training data. ii) Intermediate feature interaction: we perform cross-modal feature interaction between the video and caption to produce enhanced video representations. iii) Output score: the Query-Caption matching branch can complement the original Query-Video matching branch for text-video retrieval. We conduct comprehensive ablation studies to demonstrate the effectiveness of our approach. Without any post-processing, Cap4Video achieves state-of-the-art performance on four standard text-video retrieval benchmarks: MSR-VTT (51.4%), VATEX (66.6%), MSVD (51.8%), and DiDeMo (52.0%). The code is available at https://github.com/whwu95/Cap4Video .
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 MSR-VTT
MSR-VTT
 MSVD
MSVD
 DiDeMo
DiDeMo
 VATEX
VATEX

