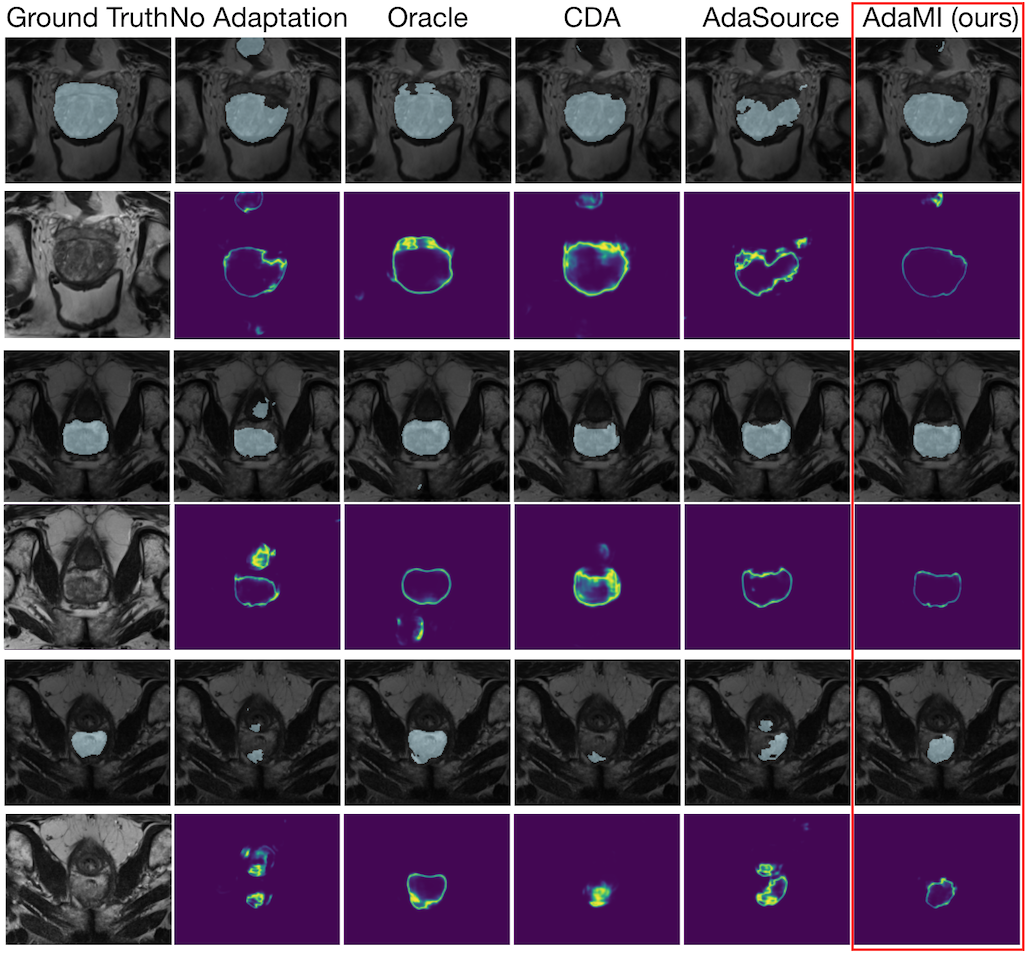
Common Limitations of Image Processing Metrics: A Picture Story
While the importance of automatic image analysis is continuously increasing, recent meta-research revealed major flaws with respect to algorithm validation. Performance metrics are particularly key for meaningful, objective, and transparent performance assessment and validation of the used automatic algorithms, but relatively little attention has been given to the practical pitfalls when using specific metrics for a given image analysis task. These are typically related to (1) the disregard of inherent metric properties, such as the behaviour in the presence of class imbalance or small target structures, (2) the disregard of inherent data set properties, such as the non-independence of the test cases, and (3) the disregard of the actual biomedical domain interest that the metrics should reflect. This living dynamically document has the purpose to illustrate important limitations of performance metrics commonly applied in the field of image analysis. In this context, it focuses on biomedical image analysis problems that can be phrased as image-level classification, semantic segmentation, instance segmentation, or object detection task. The current version is based on a Delphi process on metrics conducted by an international consortium of image analysis experts from more than 60 institutions worldwide.
PDF Abstract




