Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
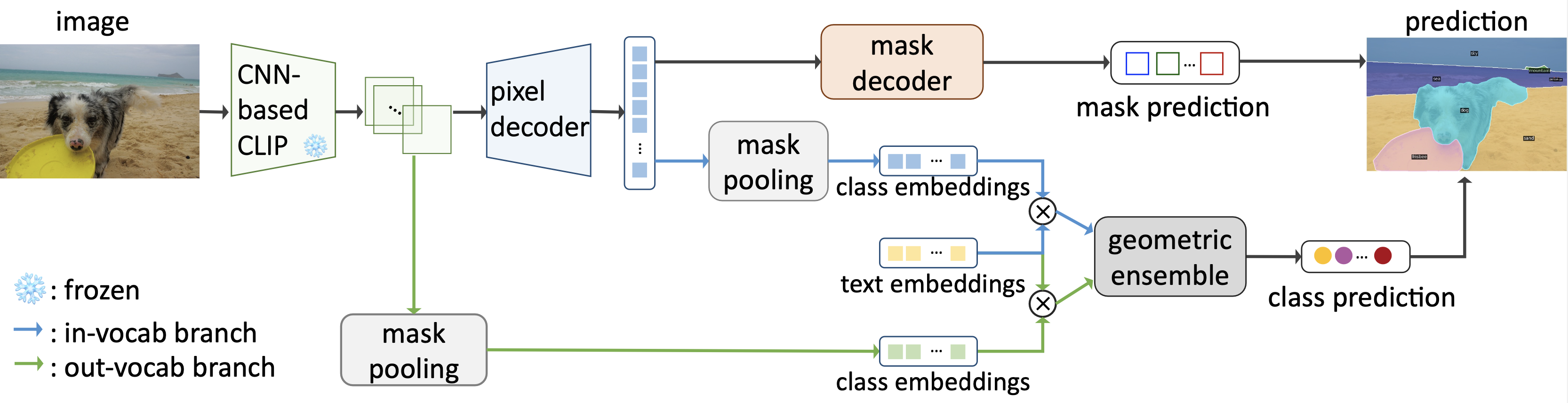
Open-vocabulary segmentation is a challenging task requiring segmenting and recognizing objects from an open set of categories. One way to address this challenge is to leverage multi-modal models, such as CLIP, to provide image and text features in a shared embedding space, which bridges the gap between closed-vocabulary and open-vocabulary recognition. Hence, existing methods often adopt a two-stage framework to tackle the problem, where the inputs first go through a mask generator and then through the CLIP model along with the predicted masks. This process involves extracting features from images multiple times, which can be ineffective and inefficient. By contrast, we propose to build everything into a single-stage framework using a shared Frozen Convolutional CLIP backbone, which not only significantly simplifies the current two-stage pipeline, but also remarkably yields a better accuracy-cost trade-off. The proposed FC-CLIP, benefits from the following observations: the frozen CLIP backbone maintains the ability of open-vocabulary classification and can also serve as a strong mask generator, and the convolutional CLIP generalizes well to a larger input resolution than the one used during contrastive image-text pretraining. When training on COCO panoptic data only and testing in a zero-shot manner, FC-CLIP achieve 26.8 PQ, 16.8 AP, and 34.1 mIoU on ADE20K, 18.2 PQ, 27.9 mIoU on Mapillary Vistas, 44.0 PQ, 26.8 AP, 56.2 mIoU on Cityscapes, outperforming the prior art by +4.2 PQ, +2.4 AP, +4.2 mIoU on ADE20K, +4.0 PQ on Mapillary Vistas and +20.1 PQ on Cityscapes, respectively. Additionally, the training and testing time of FC-CLIP is 7.5x and 6.6x significantly faster than the same prior art, while using 5.9x fewer parameters. FC-CLIP also sets a new state-of-the-art performance across various open-vocabulary semantic segmentation datasets. Code at https://github.com/bytedance/fc-clip
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 AbstractCode
 Spaces
Spaces



Datasets
 MS COCO
MS COCO
 Cityscapes
Cityscapes
 ADE20K
ADE20K
 COCO-Stuff
COCO-Stuff
 PASCAL VOC
PASCAL VOC
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Open Vocabulary Panoptic Segmentation | ADE20K | FC-CLIP | PQ | 26.8 | # 2 | |
| Open Vocabulary Semantic Segmentation | ADE20K-150 | FC-CLIP | mIoU | 34.1 | # 5 | |
| Open Vocabulary Semantic Segmentation | ADE20K-847 | FC-CLIP | mIoU | 14.8 | # 4 | |
| Open Vocabulary Semantic Segmentation | Cityscapes | FC-CLIP | mIoU | 56.2 | # 1 | |
| Open Vocabulary Semantic Segmentation | PASCAL Context-459 | FC-CLIP | mIoU | 18.2 | # 4 | |
| Open Vocabulary Semantic Segmentation | PASCAL Context-59 | FC-CLIP | mIoU | 58.4 | # 8 | |
| Open Vocabulary Semantic Segmentation | PascalVOC-20 | FC-CLIP | mIoU | 95.4 | # 5 | |
| Open Vocabulary Semantic Segmentation | PascalVOC-20b | FC-CLIP | mIoU | 81.8 | # 3 |
