DeVIS: Making Deformable Transformers Work for Video Instance Segmentation
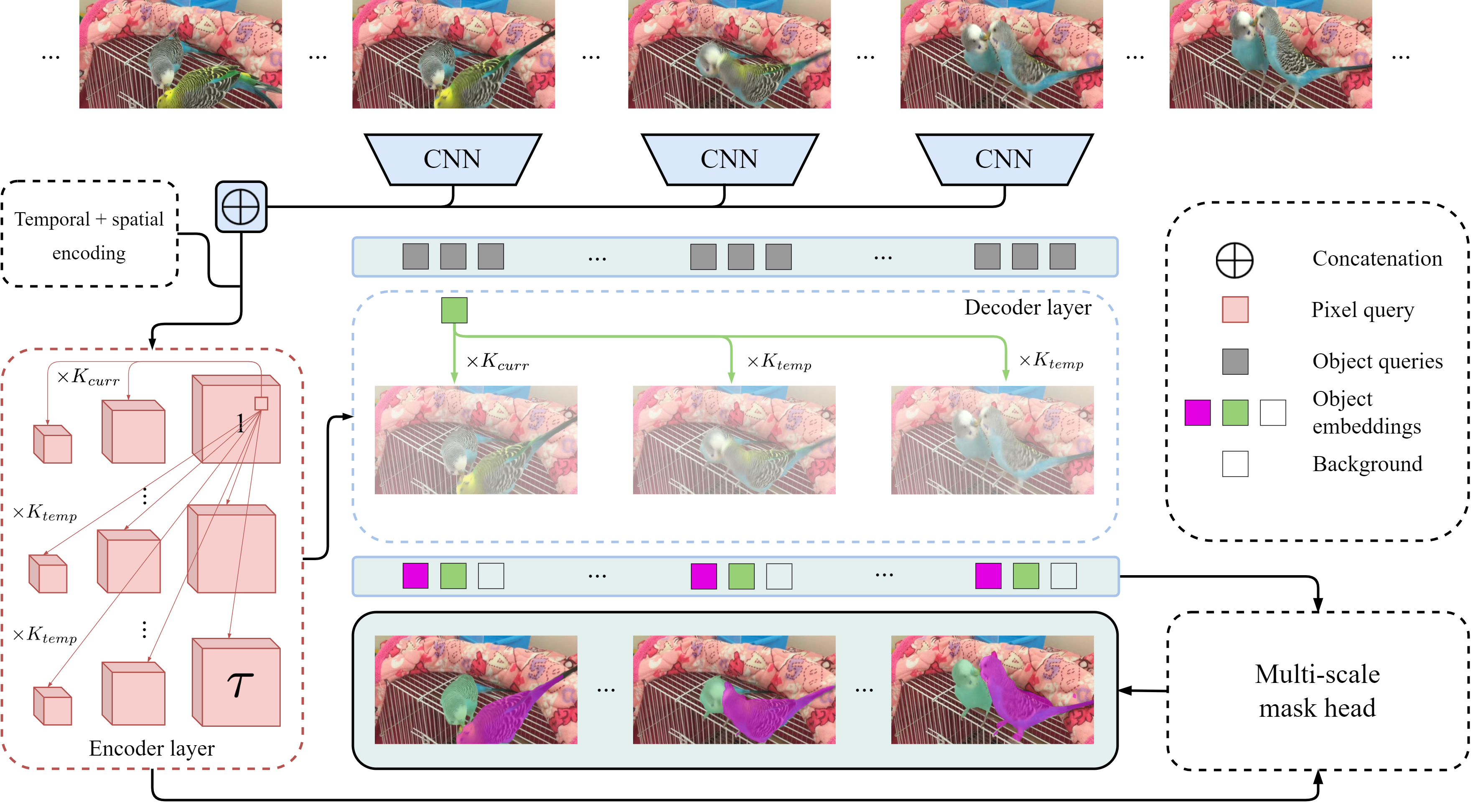
Video Instance Segmentation (VIS) jointly tackles multi-object detection, tracking, and segmentation in video sequences. In the past, VIS methods mirrored the fragmentation of these subtasks in their architectural design, hence missing out on a joint solution. Transformers recently allowed to cast the entire VIS task as a single set-prediction problem. Nevertheless, the quadratic complexity of existing Transformer-based methods requires long training times, high memory requirements, and processing of low-single-scale feature maps. Deformable attention provides a more efficient alternative but its application to the temporal domain or the segmentation task have not yet been explored. In this work, we present Deformable VIS (DeVIS), a VIS method which capitalizes on the efficiency and performance of deformable Transformers. To reason about all VIS subtasks jointly over multiple frames, we present temporal multi-scale deformable attention with instance-aware object queries. We further introduce a new image and video instance mask head with multi-scale features, and perform near-online video processing with multi-cue clip tracking. DeVIS reduces memory as well as training time requirements, and achieves state-of-the-art results on the YouTube-VIS 2021, as well as the challenging OVIS dataset. Code is available at https://github.com/acaelles97/DeVIS.
PDF Abstract





 MS COCO
MS COCO
 YouTube-VIS 2019
YouTube-VIS 2019
 OVIS
OVIS

