Evaluating Large Language Models: A Comprehensive Survey
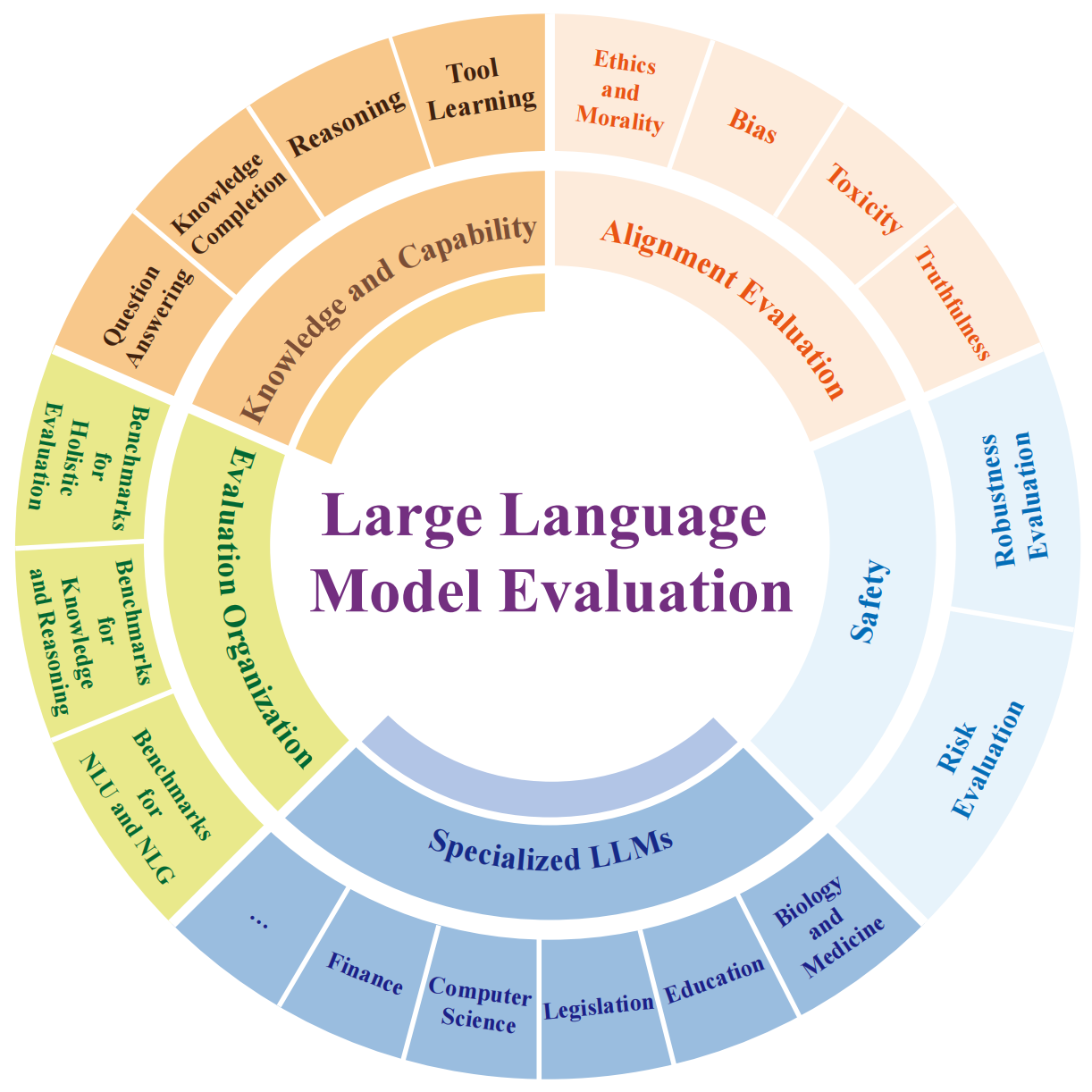
Large language models (LLMs) have demonstrated remarkable capabilities across a broad spectrum of tasks. They have attracted significant attention and been deployed in numerous downstream applications. Nevertheless, akin to a double-edged sword, LLMs also present potential risks. They could suffer from private data leaks or yield inappropriate, harmful, or misleading content. Additionally, the rapid progress of LLMs raises concerns about the potential emergence of superintelligent systems without adequate safeguards. To effectively capitalize on LLM capacities as well as ensure their safe and beneficial development, it is critical to conduct a rigorous and comprehensive evaluation of LLMs. This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs' performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability. We hope that this comprehensive overview will stimulate further research interests in the evaluation of LLMs, with the ultimate goal of making evaluation serve as a cornerstone in guiding the responsible development of LLMs. We envision that this will channel their evolution into a direction that maximizes societal benefit while minimizing potential risks. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers.
PDF AbstractCode
 Spaces
Spaces

Tasks
Datasets
 GLUE
GLUE
 MultiNLI
MultiNLI
 SNLI
SNLI
 Natural Questions
Natural Questions
 MMLU
MMLU
 GSM8K
GSM8K
 HotpotQA
HotpotQA
 HumanEval
HumanEval
 HellaSwag
HellaSwag
 MATH
MATH
 PIQA
PIQA
 OpenBookQA
OpenBookQA
 CommonsenseQA
CommonsenseQA
 XNLI
XNLI
 TruthfulQA
TruthfulQA
 NewsQA
NewsQA
 ANLI
ANLI
 CoQA
CoQA
 BIG-bench
BIG-bench
 SVAMP
LAMA
SVAMP
LAMA
 NarrativeQA
NarrativeQA
 PubMedQA
PubMedQA
 OLID
OLID
 MultiRC
ETHICS
MultiRC
ETHICS
 ALFRED
StereoSet
ALFRED
StereoSet
 WinoBias
CrowS-Pairs
SummEval
WinoBias
CrowS-Pairs
SummEval
 QASC
HELM
ASDiv
CLUE
QASC
HELM
ASDiv
CLUE
 GAP Coreference Dataset
GAP Coreference Dataset
 ReClor
ReClor
 LogiQA
LogiQA
 WikiHop
WikiHop
 ALFWorld
HybridQA
BBQ
ALFWorld
HybridQA
BBQ
 ToxiGen
MC-TACO
ToxiGen
MC-TACO
 Implicit Hate
Implicit Hate
 ToolBench
ToolBench
 HELP
AgentBench
HELP
AgentBench
 MED
Social Chemistry 101
MED
Social Chemistry 101
 MedHop
MedHop
 ProsocialDialog
ProsocialDialog
 M3KE
M3Exam
AggreFact
M3KE
M3Exam
AggreFact
 TaxiNLI
DialFact
TaxiNLI
DialFact
 TimeDial
UnQover
MMCU
VNHSGE
TimeDial
UnQover
MMCU
VNHSGE
 ToolQA
ToolQA
 JEEBench
JEEBench
 WebCPM
WebCPM
 GICoref
GICoref
