Explaining Autonomous Driving Actions with Visual Question Answering
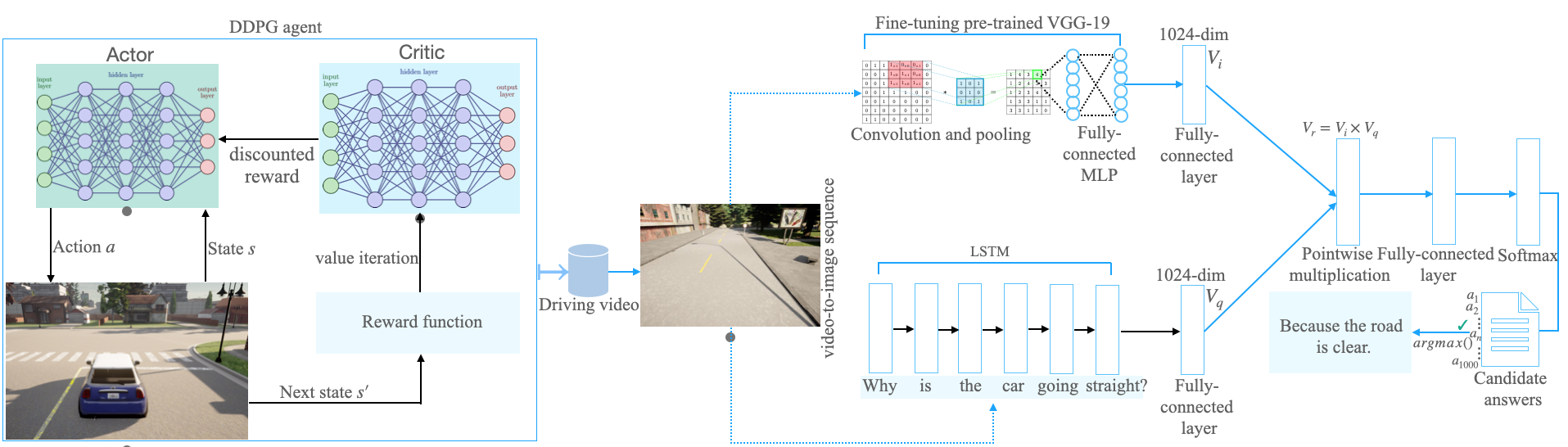
The end-to-end learning ability of self-driving vehicles has achieved significant milestones over the last decade owing to rapid advances in deep learning and computer vision algorithms. However, as autonomous driving technology is a safety-critical application of artificial intelligence (AI), road accidents and established regulatory principles necessitate the need for the explainability of intelligent action choices for self-driving vehicles. To facilitate interpretability of decision-making in autonomous driving, we present a Visual Question Answering (VQA) framework, which explains driving actions with question-answering-based causal reasoning. To do so, we first collect driving videos in a simulation environment using reinforcement learning (RL) and extract consecutive frames from this log data uniformly for five selected action categories. Further, we manually annotate the extracted frames using question-answer pairs as justifications for the actions chosen in each scenario. Finally, we evaluate the correctness of the VQA-predicted answers for actions on unseen driving scenes. The empirical results suggest that the VQA mechanism can provide support to interpret real-time decisions of autonomous vehicles and help enhance overall driving safety.
PDF Abstract





 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 CARLA
CARLA
