Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning
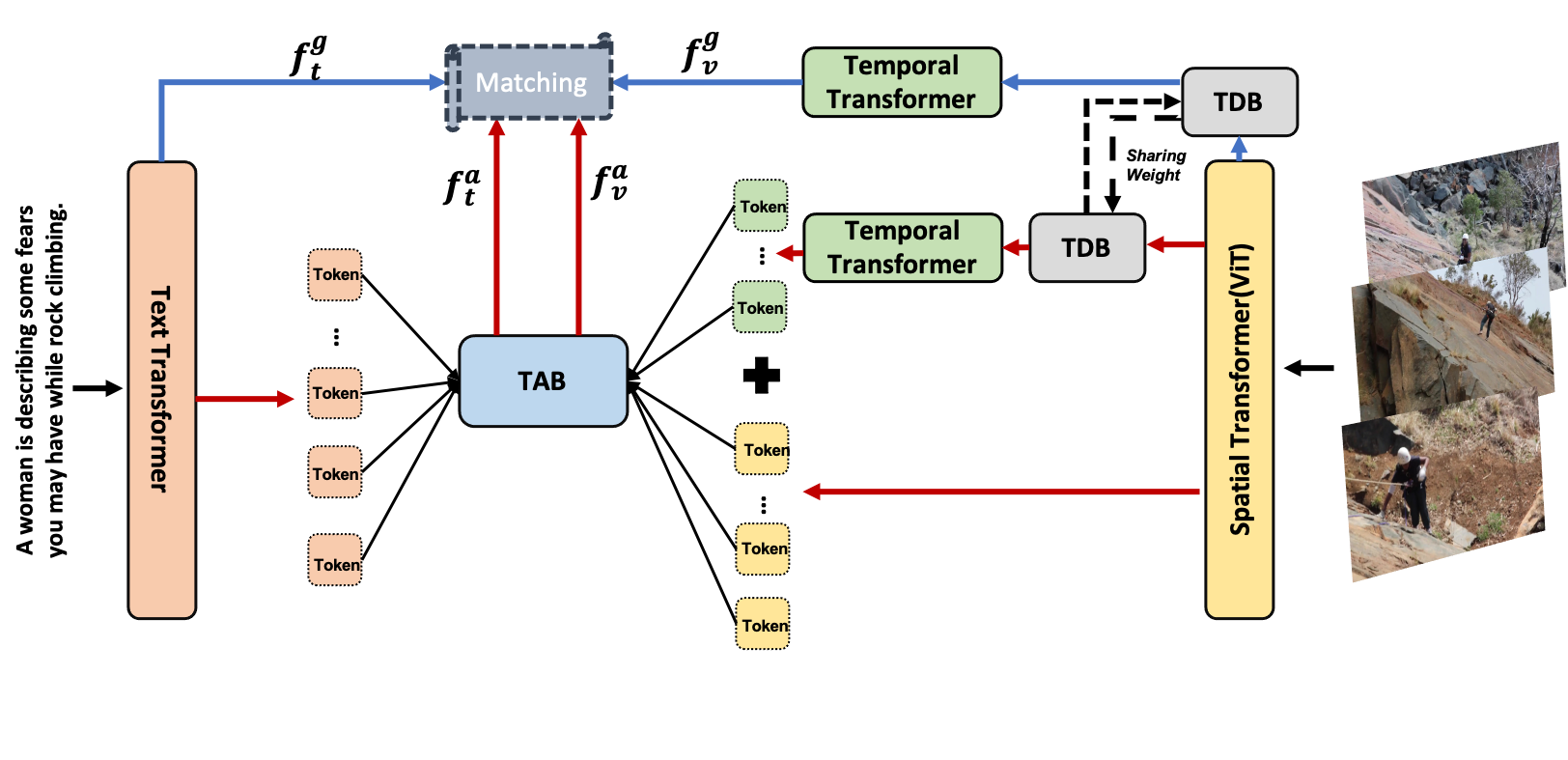
Cross-modal retrieval between videos and texts has attracted growing attentions due to the rapid emergence of videos on the web. The current dominant approach for this problem is to learn a joint embedding space to measure cross-modal similarities. However, simple joint embeddings are insufficient to represent complicated visual and textual details, such as scenes, objects, actions and their compositions. To improve fine-grained video-text retrieval, we propose a Hierarchical Graph Reasoning (HGR) model, which decomposes video-text matching into global-to-local levels. To be specific, the model disentangles texts into hierarchical semantic graph including three levels of events, actions, entities and relationships across levels. Attention-based graph reasoning is utilized to generate hierarchical textual embeddings, which can guide the learning of diverse and hierarchical video representations. The HGR model aggregates matchings from different video-text levels to capture both global and local details. Experimental results on three video-text datasets demonstrate the advantages of our model. Such hierarchical decomposition also enables better generalization across datasets and improves the ability to distinguish fine-grained semantic differences.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract

 MSR-VTT
MSR-VTT
 TGIF
TGIF
