Learning Open-vocabulary Semantic Segmentation Models From Natural Language Supervision
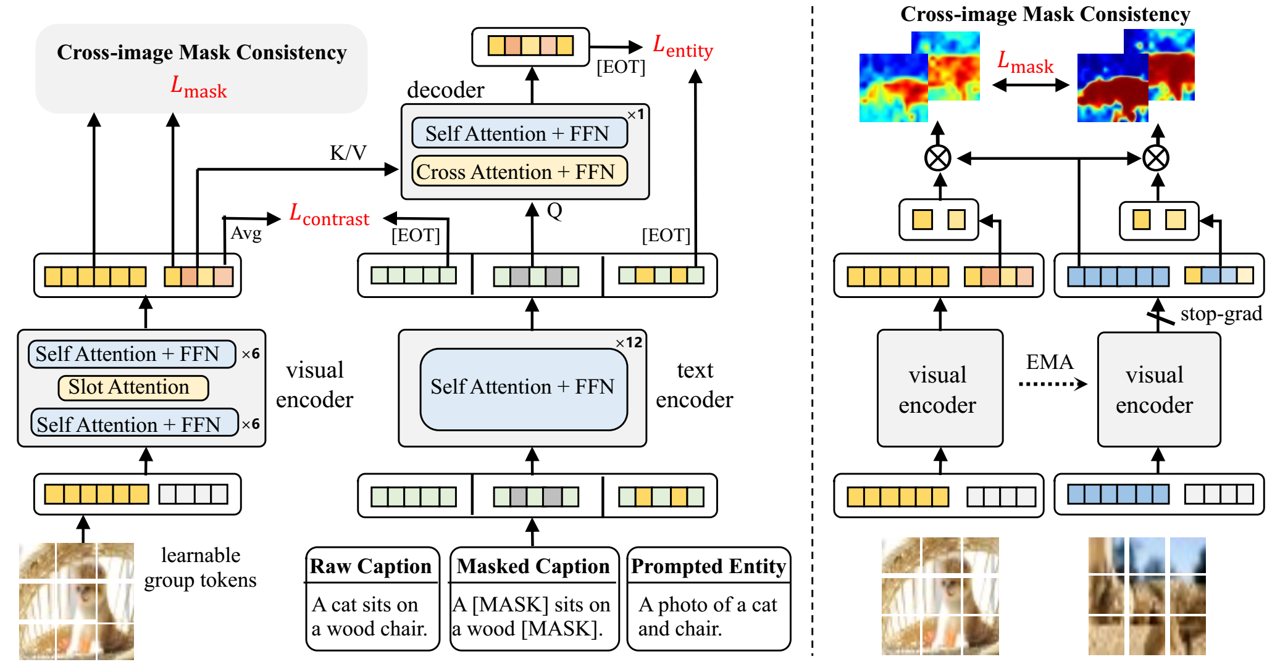
In this paper, we consider the problem of open-vocabulary semantic segmentation (OVS), which aims to segment objects of arbitrary classes instead of pre-defined, closed-set categories. The main contributions are as follows: First, we propose a transformer-based model for OVS, termed as OVSegmentor, which only exploits web-crawled image-text pairs for pre-training without using any mask annotations. OVSegmentor assembles the image pixels into a set of learnable group tokens via a slot-attention based binding module, and aligns the group tokens to the corresponding caption embedding. Second, we propose two proxy tasks for training, namely masked entity completion and cross-image mask consistency. The former aims to infer all masked entities in the caption given the group tokens, that enables the model to learn fine-grained alignment between visual groups and text entities. The latter enforces consistent mask predictions between images that contain shared entities, which encourages the model to learn visual invariance. Third, we construct CC4M dataset for pre-training by filtering CC12M with frequently appeared entities, which significantly improves training efficiency. Fourth, we perform zero-shot transfer on three benchmark datasets, PASCAL VOC 2012, PASCAL Context, and COCO Object. Our model achieves superior segmentation results over the state-of-the-art method by using only 3\% data (4M vs 134M) for pre-training. Code and pre-trained models will be released for future research.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 MS COCO
MS COCO
 PASCAL Context
PASCAL Context
