Learning Semantics for Visual Place Recognition through Multi-Scale Attention
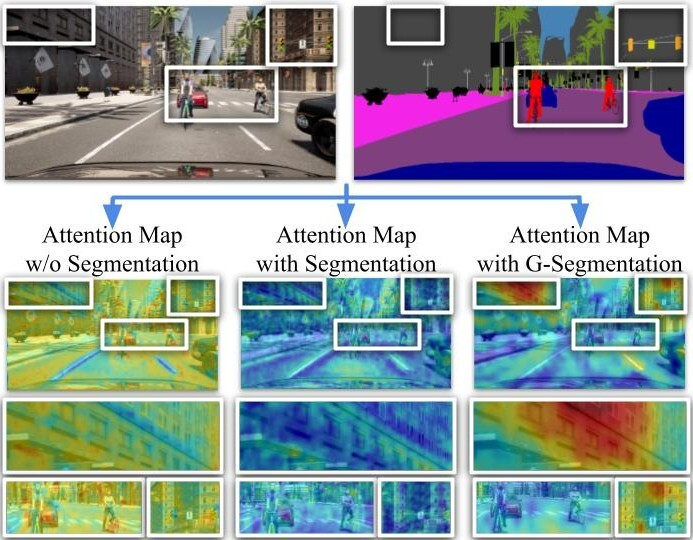
In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.
PDF Abstract


 Cityscapes
Cityscapes
 KITTI
KITTI
 CARLA
CARLA
 ADE20K
ADE20K
 Virtual KITTI 2
Virtual KITTI 2
