Learning to See the Invisible: End-to-End Trainable Amodal Instance Segmentation
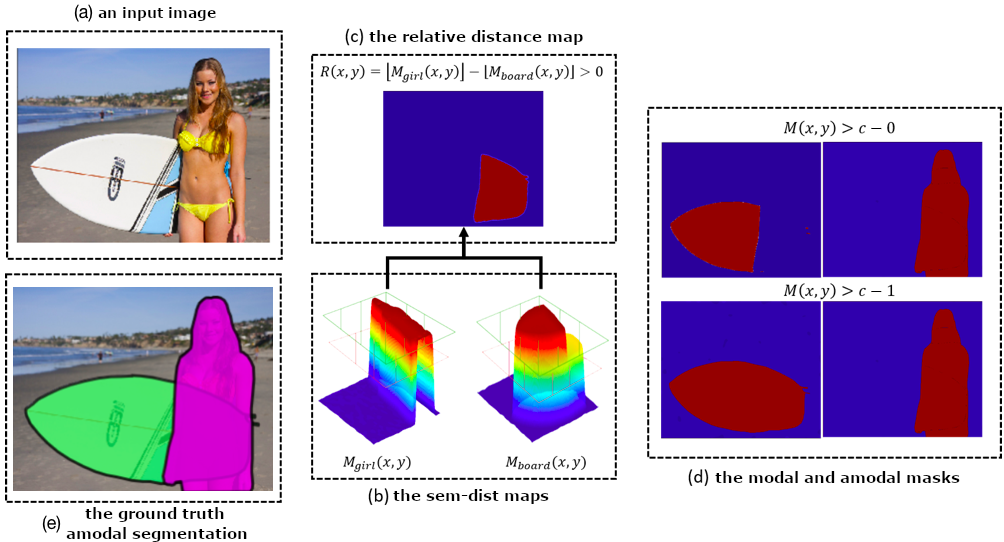
Semantic amodal segmentation is a recently proposed extension to instance-aware segmentation that includes the prediction of the invisible region of each object instance. We present the first all-in-one end-to-end trainable model for semantic amodal segmentation that predicts the amodal instance masks as well as their visible and invisible part in a single forward pass. In a detailed analysis, we provide experiments to show which architecture choices are beneficial for an all-in-one amodal segmentation model. On the COCO amodal dataset, our model outperforms the current baseline for amodal segmentation by a large margin. To further evaluate our model, we provide two new datasets with ground truth for semantic amodal segmentation, D2S amodal and COCOA cls. For both datasets, our model provides a strong baseline performance. Using special data augmentation techniques, we show that amodal segmentation on D2S amodal is possible with reasonable performance, even without providing amodal training data.
PDF Abstract




 MS COCO
MS COCO
