MDViT: Multi-domain Vision Transformer for Small Medical Image Segmentation Datasets
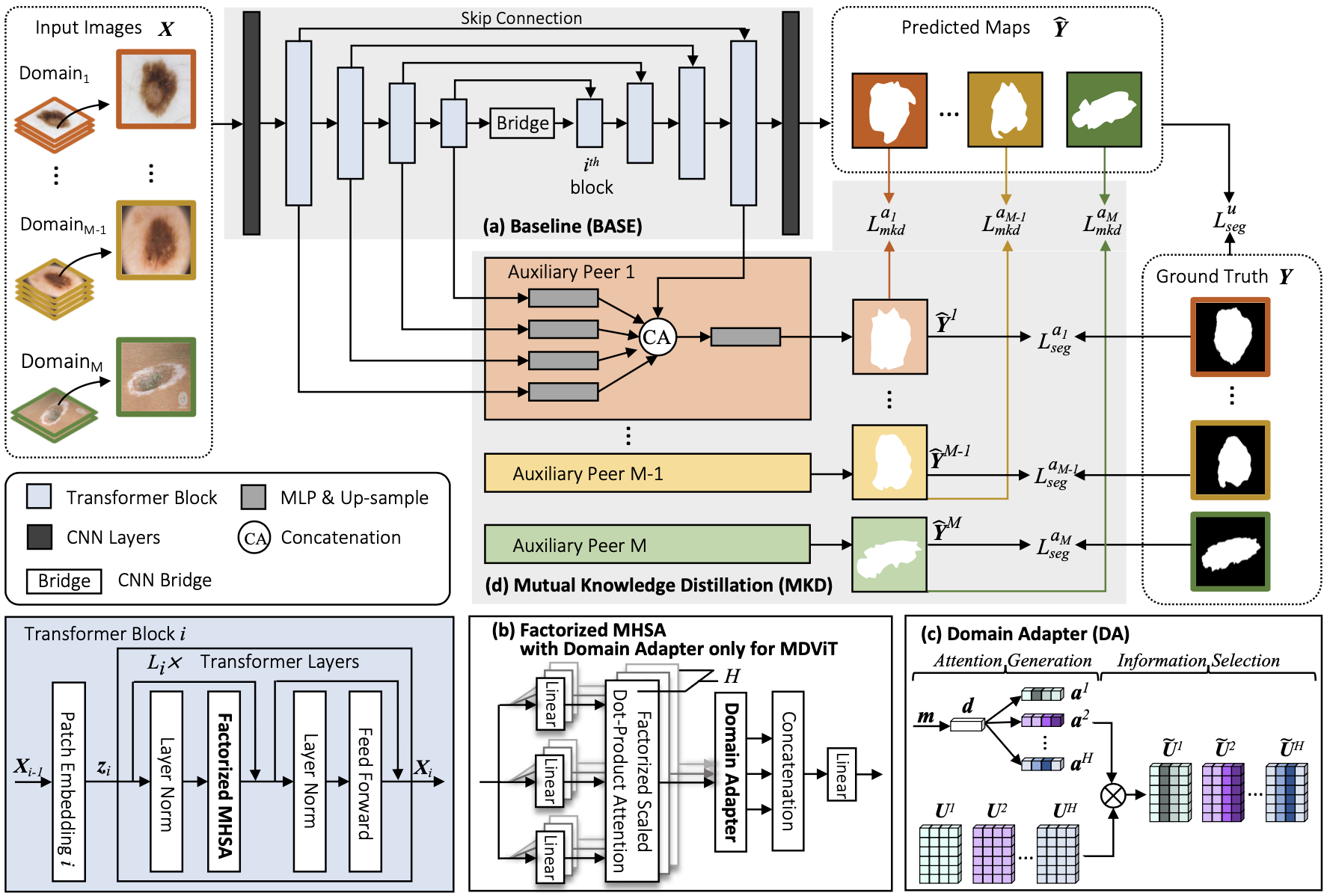
Despite its clinical utility, medical image segmentation (MIS) remains a daunting task due to images' inherent complexity and variability. Vision transformers (ViTs) have recently emerged as a promising solution to improve MIS; however, they require larger training datasets than convolutional neural networks. To overcome this obstacle, data-efficient ViTs were proposed, but they are typically trained using a single source of data, which overlooks the valuable knowledge that could be leveraged from other available datasets. Naivly combining datasets from different domains can result in negative knowledge transfer (NKT), i.e., a decrease in model performance on some domains with non-negligible inter-domain heterogeneity. In this paper, we propose MDViT, the first multi-domain ViT that includes domain adapters to mitigate data-hunger and combat NKT by adaptively exploiting knowledge in multiple small data resources (domains). Further, to enhance representation learning across domains, we integrate a mutual knowledge distillation paradigm that transfers knowledge between a universal network (spanning all the domains) and auxiliary domain-specific branches. Experiments on 4 skin lesion segmentation datasets show that MDViT outperforms state-of-the-art algorithms, with superior segmentation performance and a fixed model size, at inference time, even as more domains are added. Our code is available at https://github.com/siyi-wind/MDViT.
PDF Abstract






