PanoVPR: Towards Unified Perspective-to-Equirectangular Visual Place Recognition via Sliding Windows across the Panoramic View
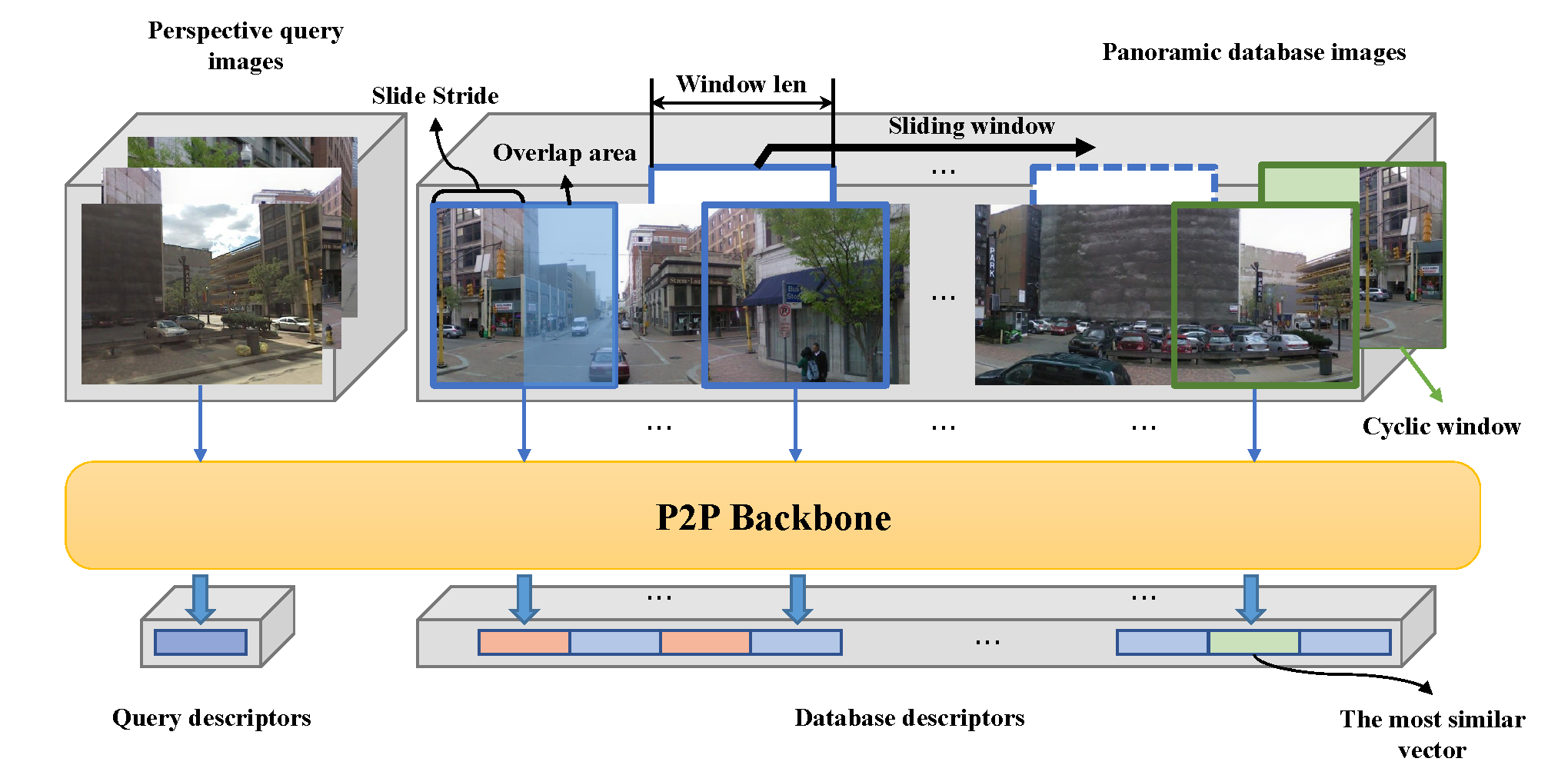
Visual place recognition has gained significant attention in recent years as a crucial technology in autonomous driving and robotics. Currently, the two main approaches are the perspective view retrieval (P2P) paradigm and the equirectangular image retrieval (E2E) paradigm. However, it is practical and natural to assume that users only have consumer-grade pinhole cameras to obtain query perspective images and retrieve them in panoramic database images from map providers. To address this, we propose \textit{PanoVPR}, a perspective-to-equirectangular (P2E) visual place recognition framework that employs sliding windows to eliminate feature truncation caused by hard cropping. Specifically, PanoVPR slides windows over the entire equirectangular image and computes feature descriptors for each window, which are then compared to determine place similarity. Notably, our unified framework enables direct transfer of the backbone from P2P methods without any modification, supporting not only CNNs but also Transformers. To facilitate training and evaluation, we derive the Pitts250k-P2E dataset from the Pitts250k and establish YQ360, latter is the first P2E visual place recognition dataset collected by a mobile robot platform aiming to simulate real-world task scenarios better. Extensive experiments demonstrate that PanoVPR achieves state-of-the-art performance and obtains 3.8% and 8.0% performance gain on Pitts250k-P2E and YQ360 compared to the previous best method, respectively. Code and datasets will be publicly available at https://github.com/zafirshi/PanoVPR.
PDF Abstract




