Probing Conceptual Understanding of Large Visual-Language Models
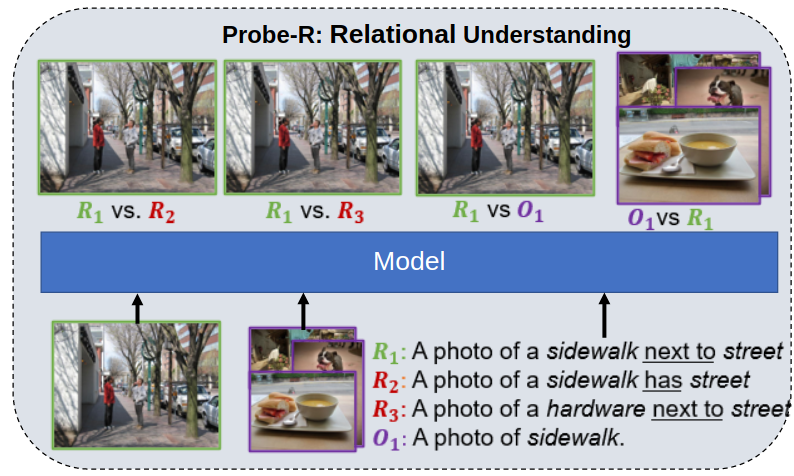
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) \textit{relations}, 2) \textit{composition}, and 3) \textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly \textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that \textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with \textit{texture and patterns}, while Transformers are better at \textit{color and shape}. We further utilize some of these insights and investigate a \textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: \url{https://tinyurl.com/vlm-robustness}
PDF Abstract

 MS COCO
MS COCO
 Visual Genome
Visual Genome
