Profiling Neural Blocks and Design Spaces for Mobile Neural Architecture Search
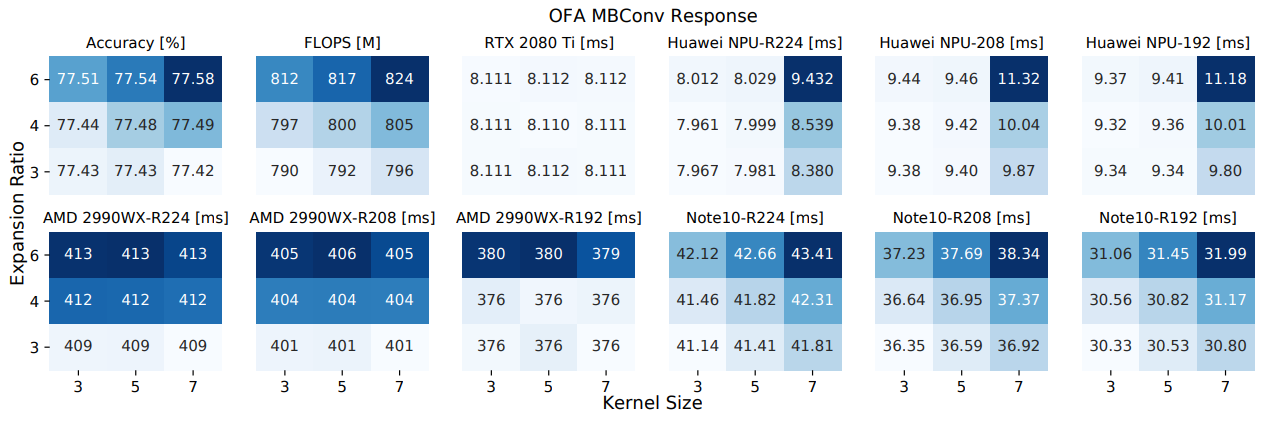
Neural architecture search automates neural network design and has achieved state-of-the-art results in many deep learning applications. While recent literature has focused on designing networks to maximize accuracy, little work has been conducted to understand the compatibility of architecture design spaces to varying hardware. In this paper, we analyze the neural blocks used to build Once-for-All (MobileNetV3), ProxylessNAS and ResNet families, in order to understand their predictive power and inference latency on various devices, including Huawei Kirin 9000 NPU, RTX 2080 Ti, AMD Threadripper 2990WX, and Samsung Note10. We introduce a methodology to quantify the friendliness of neural blocks to hardware and the impact of their placement in a macro network on overall network performance via only end-to-end measurements. Based on extensive profiling results, we derive design insights and apply them to hardware-specific search space reduction. We show that searching in the reduced search space generates better accuracy-latency Pareto frontiers than searching in the original search spaces, customizing architecture search according to the hardware. Moreover, insights derived from measurements lead to notably higher ImageNet top-1 scores on all search spaces investigated.
PDF Abstract

 NAS-Bench-101
NAS-Bench-101
