Reusing Convolutional Activations from Frame to Frame to Speed up Training and Inference
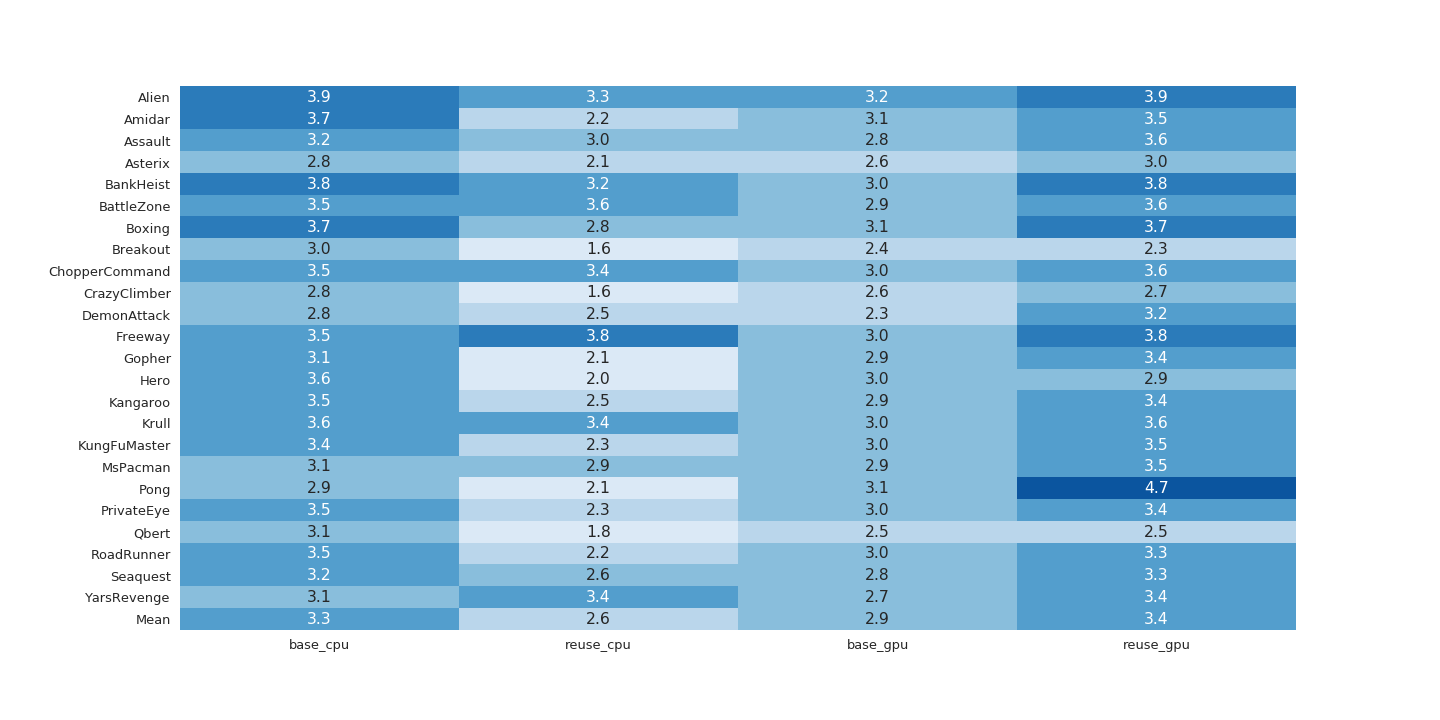
When processing similar frames in succession, we can take advantage of the locality of the convolution operation to reevaluate only portions of the image that changed from the previous frame. By saving the output of a layer of convolutions and calculating the change from frame to frame, we can reuse previous activations and save computational resources that would otherwise be wasted recalculating convolutions whose outputs we have already observed. This technique can be applied to many domains, such as processing videos from stationary video cameras, studying the effects of occluding or distorting sections of images, applying convolution to multiple frames of audio or time series data, or playing Atari games. Furthermore, this technique can be applied to speed up both training and inference.
PDF Abstract



