Revisiting the Sibling Head in Object Detector
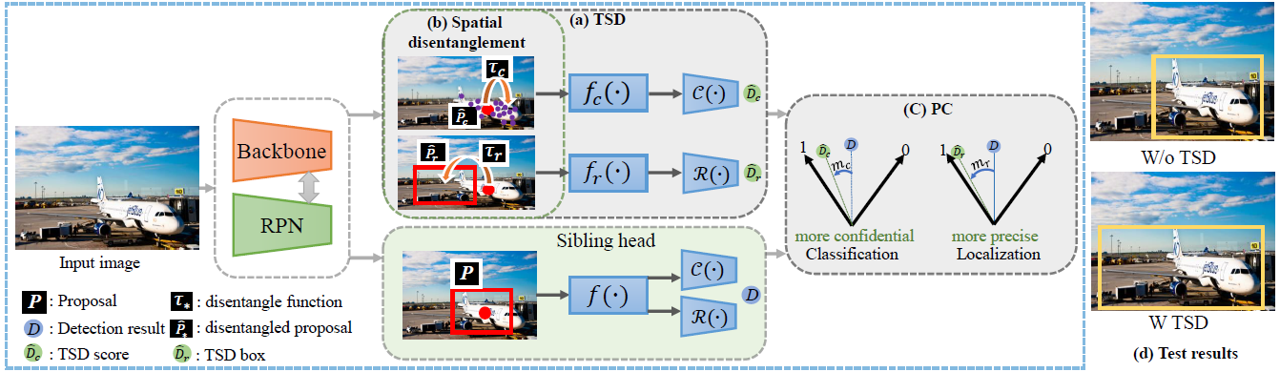
The ``shared head for classification and localization'' (sibling head), firstly denominated in Fast RCNN~\cite{girshick2015fast}, has been leading the fashion of the object detection community in the past five years. This paper provides the observation that the spatial misalignment between the two object functions in the sibling head can considerably hurt the training process, but this misalignment can be resolved by a very simple operator called task-aware spatial disentanglement (TSD). Considering the classification and regression, TSD decouples them from the spatial dimension by generating two disentangled proposals for them, which are estimated by the shared proposal. This is inspired by the natural insight that for one instance, the features in some salient area may have rich information for classification while these around the boundary may be good at bounding box regression. Surprisingly, this simple design can boost all backbones and models on both MS COCO and Google OpenImage consistently by ~3% mAP. Further, we propose a progressive constraint to enlarge the performance margin between the disentangled and the shared proposals, and gain ~1% more mAP. We show the \algname{} breaks through the upper bound of nowadays single-model detector by a large margin (mAP 49.4 with ResNet-101, 51.2 with SENet154), and is the core model of our 1st place solution on the Google OpenImage Challenge 2019.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract



 MS COCO
MS COCO

