SAM: Self-supervised Learning of Pixel-wise Anatomical Embeddings in Radiological Images
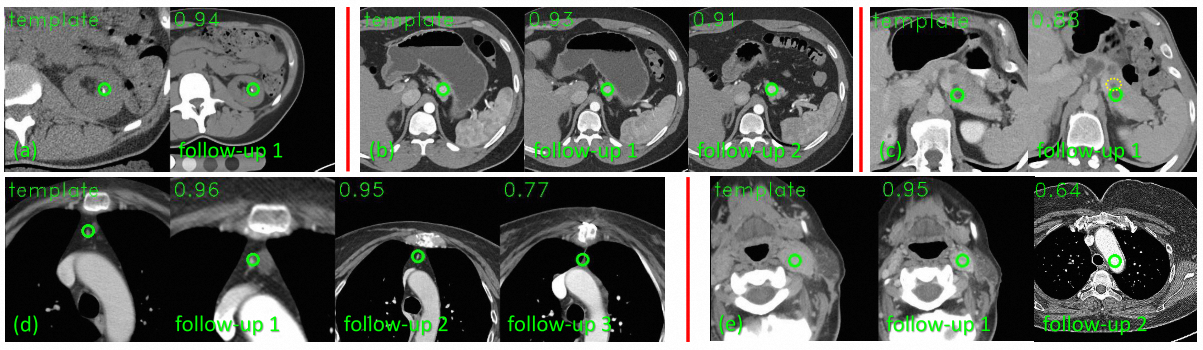
Radiological images such as computed tomography (CT) and X-rays render anatomy with intrinsic structures. Being able to reliably locate the same anatomical structure across varying images is a fundamental task in medical image analysis. In principle it is possible to use landmark detection or semantic segmentation for this task, but to work well these require large numbers of labeled data for each anatomical structure and sub-structure of interest. A more universal approach would learn the intrinsic structure from unlabeled images. We introduce such an approach, called Self-supervised Anatomical eMbedding (SAM). SAM generates semantic embeddings for each image pixel that describes its anatomical location or body part. To produce such embeddings, we propose a pixel-level contrastive learning framework. A coarse-to-fine strategy ensures both global and local anatomical information are encoded. Negative sample selection strategies are designed to enhance the embedding's discriminability. Using SAM, one can label any point of interest on a template image and then locate the same body part in other images by simple nearest neighbor searching. We demonstrate the effectiveness of SAM in multiple tasks with 2D and 3D image modalities. On a chest CT dataset with 19 landmarks, SAM outperforms widely-used registration algorithms while only taking 0.23 seconds for inference. On two X-ray datasets, SAM, with only one labeled template image, surpasses supervised methods trained on 50 labeled images. We also apply SAM on whole-body follow-up lesion matching in CT and obtain an accuracy of 91%. SAM can also be applied for improving image registration and initializing CNN weights.
PDF Abstract






