Structured Triplet Learning with POS-tag Guided Attention for Visual Question Answering
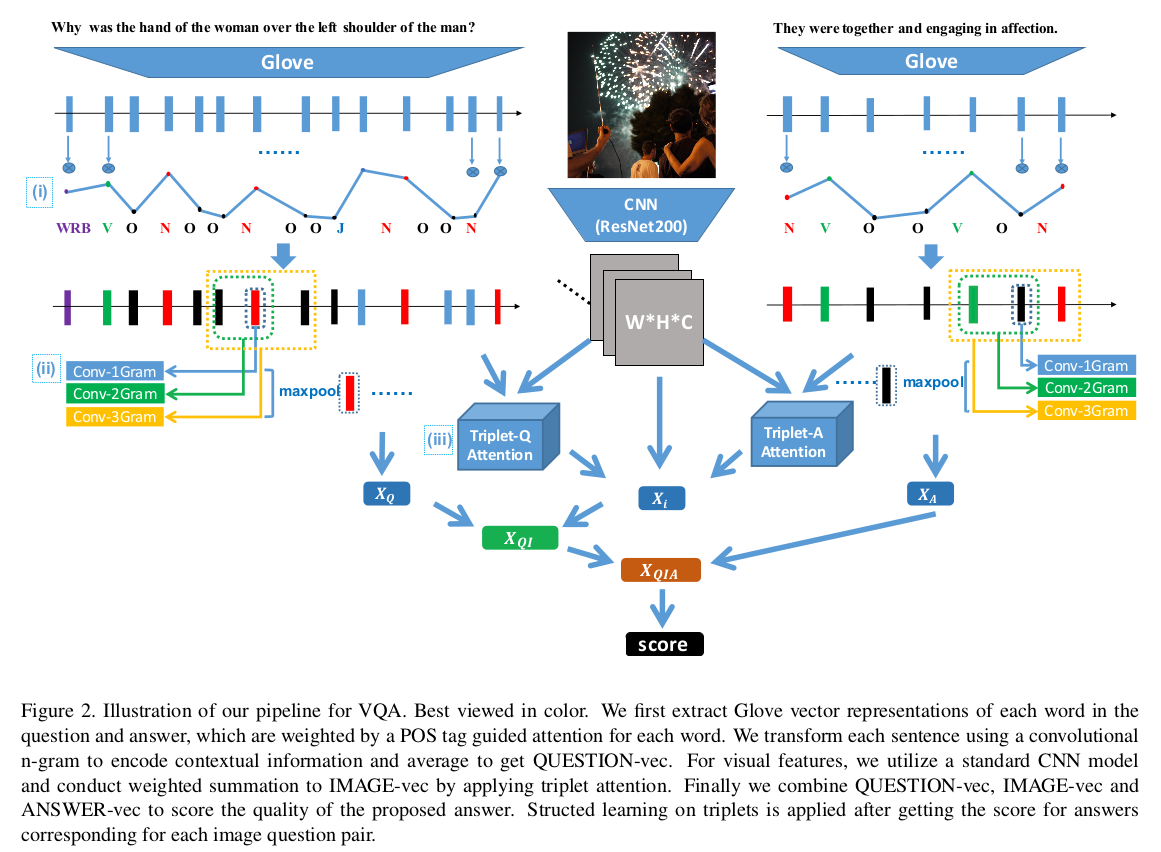
Visual question answering (VQA) is of significant interest due to its potential to be a strong test of image understanding systems and to probe the connection between language and vision. Despite much recent progress, general VQA is far from a solved problem. In this paper, we focus on the VQA multiple-choice task, and provide some good practices for designing an effective VQA model that can capture language-vision interactions and perform joint reasoning. We explore mechanisms of incorporating part-of-speech (POS) tag guided attention, convolutional n-grams, triplet attention interactions between the image, question and candidate answer, and structured learning for triplets based on image-question pairs. We evaluate our models on two popular datasets: Visual7W and VQA Real Multiple Choice. Our final model achieves the state-of-the-art performance of 68.2% on Visual7W, and a very competitive performance of 69.6% on the test-standard split of VQA Real Multiple Choice.
PDF Abstract



 Visual Question Answering
Visual Question Answering
 Visual7W
Visual7W
